斯坦福NLP教材第八章
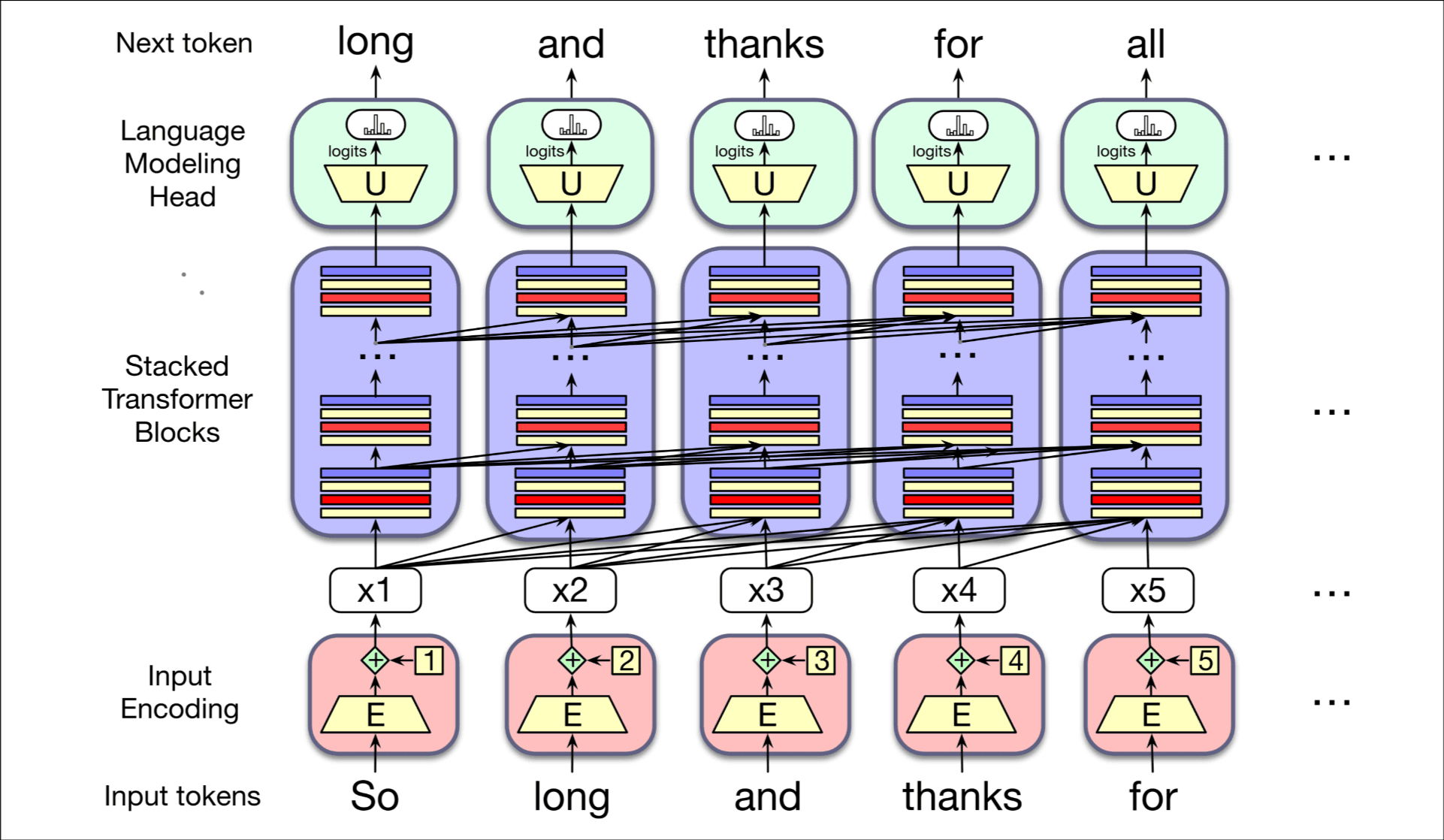
讲了一下Transformer的基本结构, 通过当前词预测下一个词, 下面是一个嵌入矩阵E, 将词映射到有意义的向量空间; 中间是堆叠的Transformer块, 输入和输出的长度(输入的context window和输出的context window)相等; 结尾是一个unembedding 矩阵U和一个softmax每列生成唯一的token.
Attention
- The chicken didn’t cross the road because it was too tired.
- The chicken didn’t cross the road because it was too wide.
- The chicken didn’t cross the road because it
- The keys to the cabinet are on the table.
- I walked along the pond, and noticed one of the trees along the bank.
注意上面这些例子, 1和2在不同情境下it表示不同的含义, 3在没有上下文时不能判断it指代什么, 4根据The keys决定用are还是is, 5中bank有河岸也有银行的意思, 根据前面的pond知道这里是河岸的意思.
想表达的观点是: 在前面我们学习了通过嵌入将词映射到固定的向量表示, 而Transformer可以构建词含义的上下文词含义表示. Attention是Transformer中的一种机制, 它通过对上下文中适当其他标记的表示进行加权和组合, 来构建第k+1层中各标记的表示. 看下面这个图, 表示it需要关于chicken更多的权重, 关于road更少的权重.
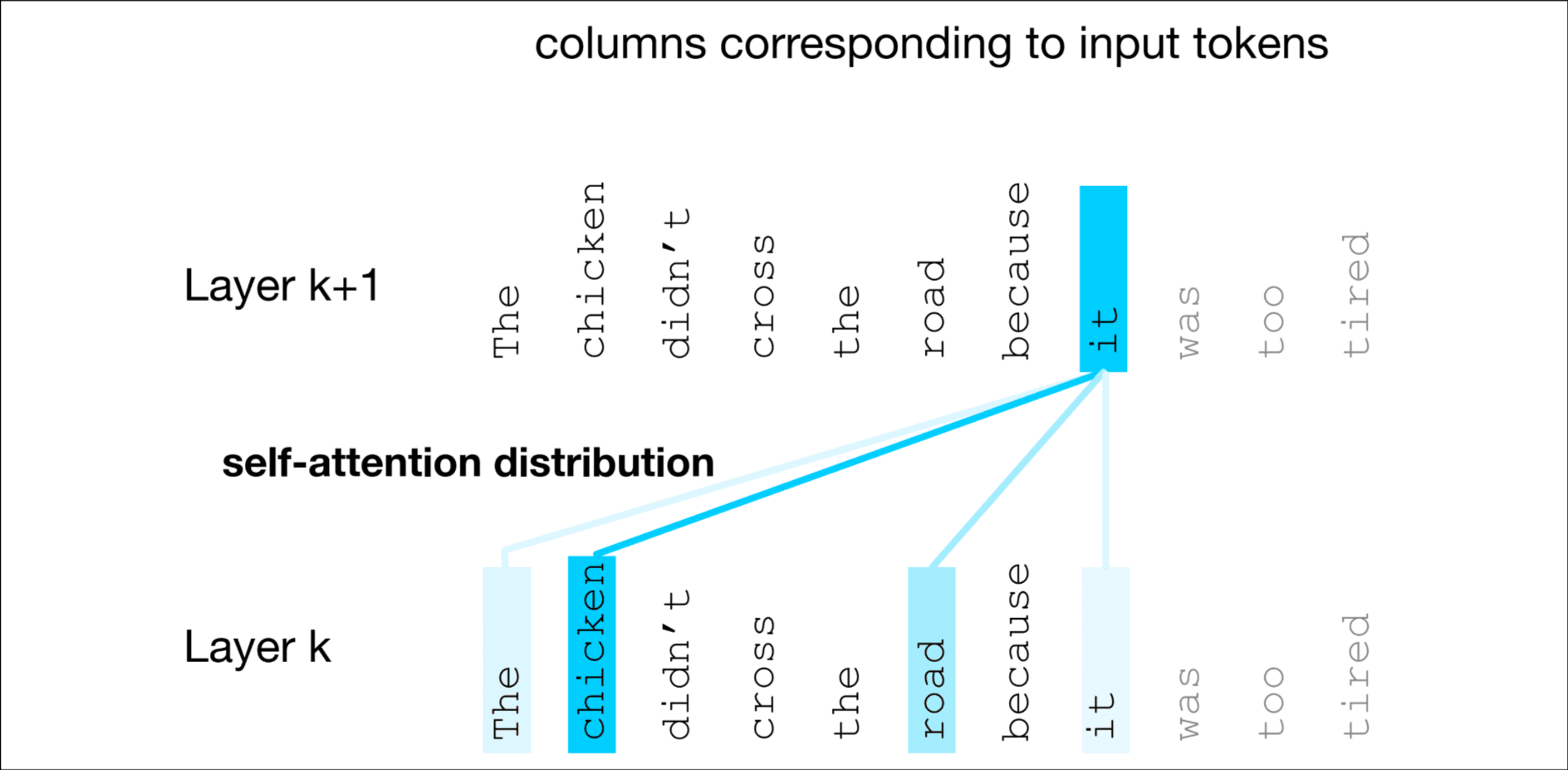
接下来看看要怎么计算注意力
在causal attention中(中文叫因果注意力), 上下文是所有前序单词, 当处理是, 模型只可以访问i以前的token(weight).
简化版本的attention, 输入用x表示, 输出用a表示, 表示对贡献多少, 公式表示
这样问题转换成了怎么计算标量, 这里一个简化版本是计算和的相似度, 用点乘, 再过softmax, 和自身的点乘很高, 可以保留较高的weight
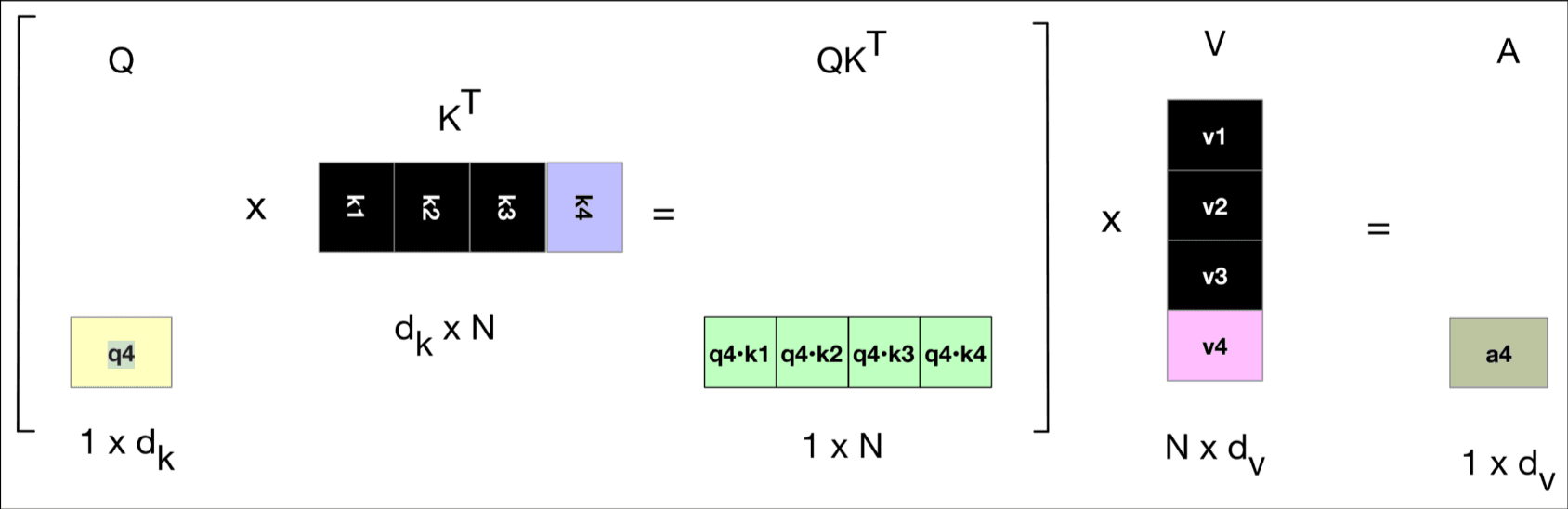
使用query, key, value矩阵的单注意力头. 个人觉得强行解释qkv的作用没有意义, 只要知道qk点乘计算一个score, 处理后和v矩阵乘就行了, 下面是相关的公式
多头注意力. 每个头关注context有不同的目的. 每个头有它自己的qkv矩阵, 原始Transformer paper中 , 计算公式就免了, 很清楚.
Transformer Block
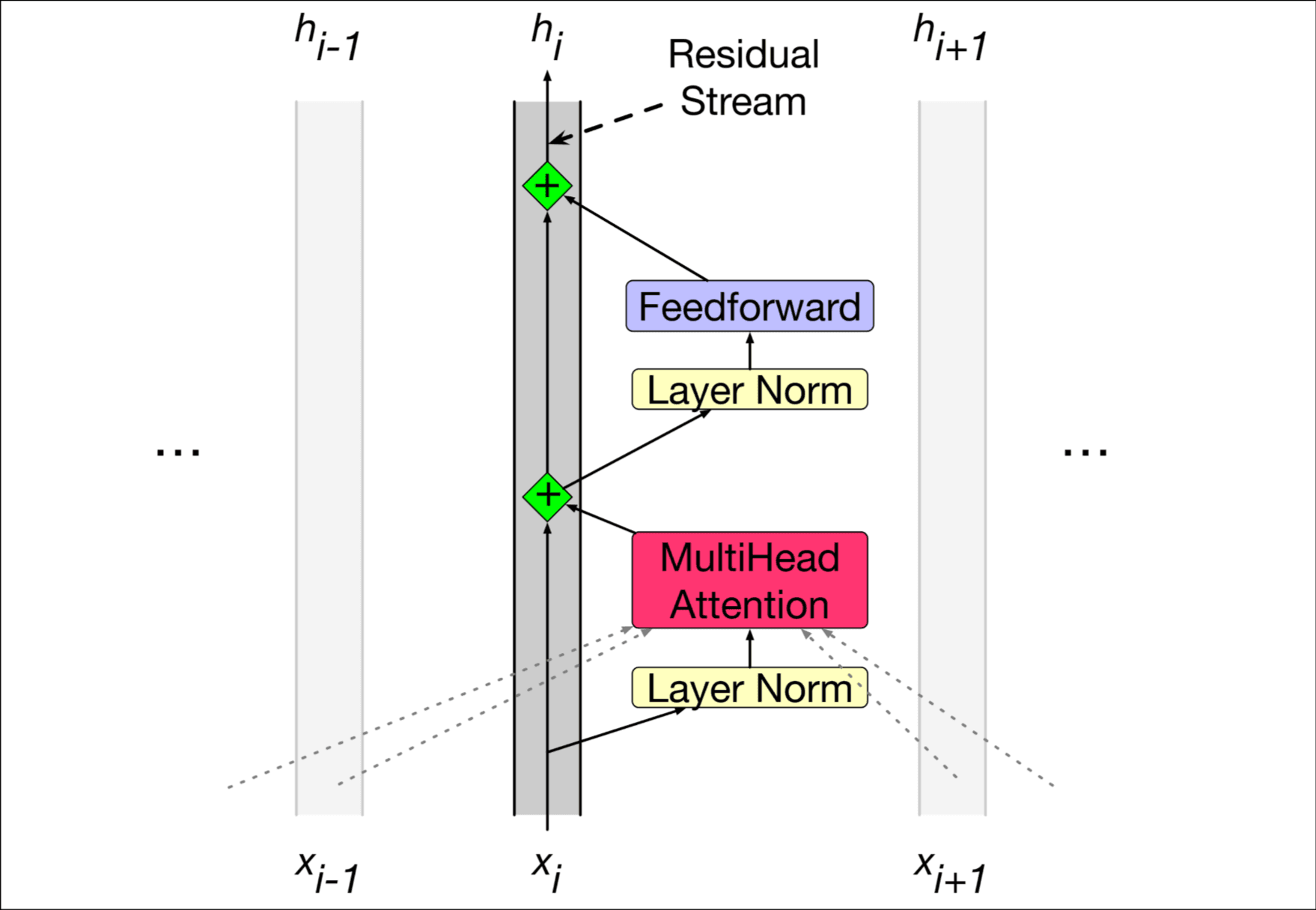
上图很清楚, 多头注意力是核心, 还包括feedforward layer, residual connection, normalizing layer.
残差连接. 讲了一个residual stream的观点, 没有get到点, 可能就是表述了一下这中输入残差, 在把结果与残差流相加的结构吧.
Feedforward Layer. 一个全连接两层网络, 公式如下
Layer Norm. "Layer"指单一向量的嵌入维度, 使它的均值为, 方差为
有一个观点说attention heads就是把其他token的residual stream的信息移动到当前token, 真实的语言模型包含很多层Transformer块, 在前面的Transformer块表示当前token的信息, 在后面的Transformer块表示下一个token的信息, 毕竟语言模型要做预测任务.
Parallelizing computation using a single matrix X
噢, 前面只针对计算单次输出, 我都没注意, 这一节他考虑使用矩阵并行计算, 因为不依赖相邻位置的值.
这一节内容已经很熟悉了跳过, 把attention变成了矩阵运算罢了.
The input: embeddings for token and position
token embeddings. embedding matrix E存储了每一个词的位置嵌入, 假如一个句子"Thanks for all the", 转换为词汇表索引比如[5, 4000, 10532, 2224] -> 转换为对应的one-hot编码 -> 与E矩阵乘得到最终的嵌入.
positional embeddings. token embedding得到的token是位置无关的, 我们对每个token加上不同位置的位置编码, 这里的位置编码说是随机生成的, 但是可训练. 这样存在一个问题, 靠后的位置编码因为样本长度的限制更少参与训练, 于是考虑用静态位置嵌入, sine and cosine function.
The Language Modeling Head
注意到在模型的输入端, 我们对句子的one-hot编码矩阵乘了一个嵌入矩阵E, 作为token表示, 那么在输出端, 我们对Transformer Block的输入矩阵乘记为U, 常被称作unembedding, 希望把token表示转换为概率, E会经过训练变得擅长处理这种任务.
经过softmax得到的是这个位置为词汇表每个词的概率, 但我们最终任务是生成文本, 我们要从概率y中采样一个单词, 最简单的方法是取概率最高的词.
接着阐述了当前介绍的是decoder-only model, 12章会介绍encoder-decoder model用于翻译任务.
More on Sampling
要综合考虑质量和多样性.
Top-k sampling. 选择最有可能的k个词, 重新计算概率, 根据概率随机选择一个词.
Top-p sampling. 选择前k个词, 使总概率大于p, 没什么好说的.
Training
提到训练最重要的当然是损失函数了, 用的cross-entropy loss, 序列长度假如是N, 输出序列长度也是N, 每个词计算一个cross-entropy, 取平均值作为loss.
大语言模型在全上下文窗口中训练, 如果长度不够, 有一个特别的end-of-text token.
Dealing with Scale
大语言模型的参数量非常大, 下面讨论scale law, 研究怎么让LLM高效的工作.
scaling laws. 大语言模型的表现取决于三个方面, 模型大小, 数据集大小, 总计算量, 模型表现和这三个factor的关系叫做scaling laws. 这个laws可以帮助我们搞清楚怎么改善模型表现说是.
KV Cache. 背景是在训练阶段我们通过矩阵计算注意力很高效, 但是在推理阶段, word是逐词生成的, 假如我刚刚生成了一个新的word , 现在通过, , 计算了query, key, value, 如果我们还是用下面的矩阵计算就浪费计算资源了.
这里感觉书本上没讲清楚, 问GPT为什么Q不用缓存回答也是依托 但是这个图挺清楚的, 我现在预测, 注意我在这一个时间步只在乎的值, 这意味着, , , 我都不需要参与计算, 这就是为什么叫KV-cache, 而不是QKV-cache.
Parameter Efficient Fine Tuning. 选择部分参数更新来微调模型, 介绍了LoRA, 这里详细讲一下吧, Transformer块中有许多的矩阵, 假如其中一个矩阵是W, shape为[N, d], 我们希望微调后矩阵我们记为, 表示W的改变量, 代替训练原矩阵, 我们训练AB, A的shape为[N, r], B的shape为[r, d], 这样做的好处是A+B的参数量远小于W, 更容易训练.
Interpreting the Transformer
这一节探讨为什么Transformer的效果那么好, 介绍了两种对它的研究.
In-Context Learning and Induction Heads. 我有点没看懂它要讲什么, 它说pretrain和prompt是模型学习的方式, pretrain通过梯度下降更新参数学习, prompt with demonstrations 可以教模型新的任务. 然后即使没有demonstrations, prompt越长, 预测也会越准. In-Context Learning指模型从提示词中学习, (是想讲提示词工程?), 后面它像是在举一个例子, induction heads, 就是他们会学习prompt中相似的模式, 并在后续生成中重复这个模式, 并通过消融实验证明了这种猜想. 彩蛋: 消融实验中的ablation原来是一个医学term表示removal of something.
Logit Lens. 这个很简单, 我们从transformer的任何一层中取出任意向量, 并假装它是倒数第二层的嵌入, 只需将其与解嵌层相乘即可得到logits, 然后计算softmax以查看该向量可能代表的词分布. 不是一直有用.