
很多人都有过视觉灵感的闪现, 得益于text-to-image diffusion模型的进步, 现在可以根据一段prompt生成视觉震惊的图片, 但是这种方法限制了空间的表达, 可能需要反复修改提示词才能得到满意的图片.
引出问题: 能不能让用户提供额外的图片直接定制他们想要的图片组成. 介绍当前这方面的研究, 在机器学习中这种控制信号包括边缘图, 人类姿势骨骼, 分割图, 深度图, 等等. 接着举例了在image-to-image方面的研究, 社区的一些研究. 指出问题: 要求端到端的学习和数据驱动.
介绍添加额外控制信号的难点:数据少, 在大预训练模型上微调, 如果数据太少会导致过拟合和灾难性的遗忘. 可以通过限制参数的数量或等级缓解.
ControlNet冰冻sd的参数来保持生成图片的质量和能力, 同时复制编码层的参数. 可复制的编码器副本和原网络通过零卷积连接, 卷积参数阶段性提高, 然后讲了一下这样做的好处.
讲效果: ControlNet可以接受多种控制信号, 可以接受多种控制信号同时控制, 不同大小数据集上表现健壮性, 计算要求最低3090.
HyperNetwork. 用一个小的循环神经网络影响大的神经网络.
Adapter. 上一篇DreamPose就是用的这个, 一个示例是把图片通过CLIP和VAE的输出对齐(Flatten).
Additive Learning. 感觉和残差有点像, 冻结原网络参数防止遗忘, 添加一部分参数.
LoRA. 观察到很多模型的参数都是过多的, 通过一个低秩矩阵学习参数的偏移量.
零初始化层. ControlNet使用的方法, 然后引用了一些案例.
Image Diffusion Models. LDM, CLIP, stable diffusion这些.
Controlling Image Diffusion Models. 介绍调提示词, 分割掩码, 一组图片上下文这些方法.
就介绍了几种模型.
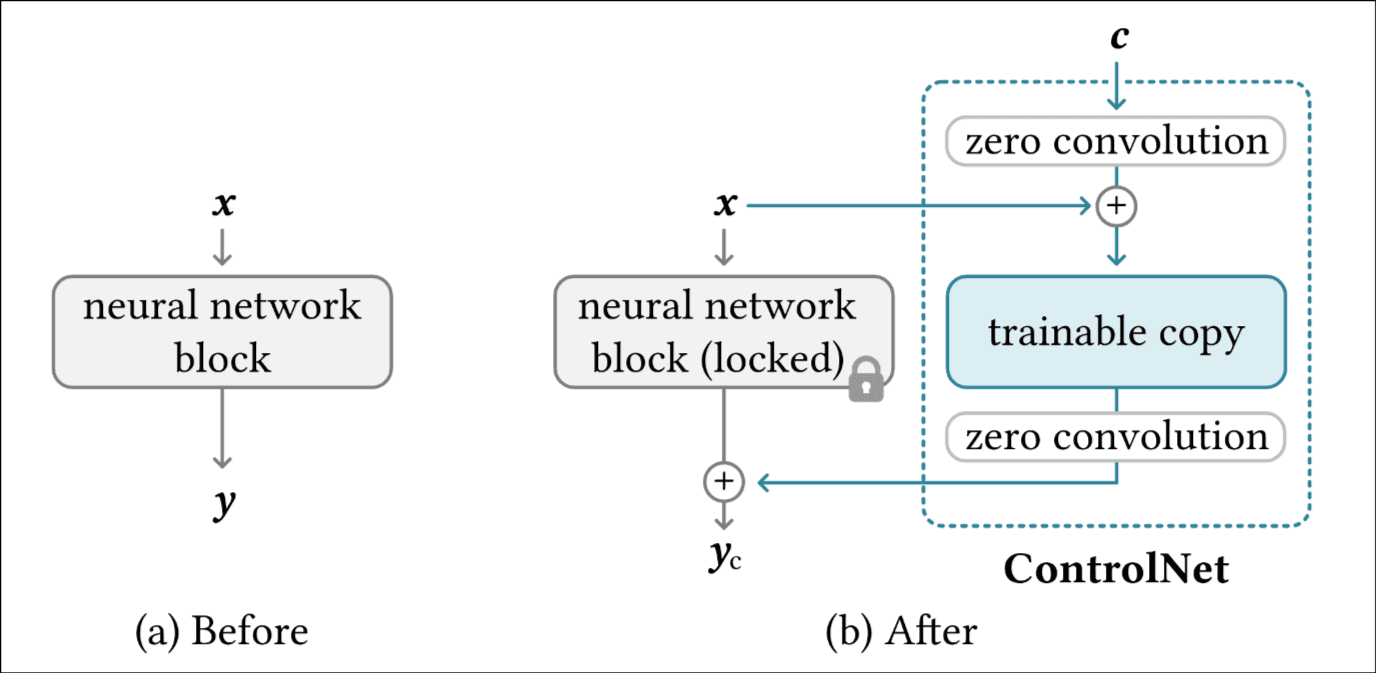
就讲了一个事情, 如上图左侧灰色是原神经网络, 为了防止遗忘, 冰冻参数. 为了增加新的控制信号c, 克隆原block的参数用于训练, 这里的解释是:"重复利用参数可以建立一个深的, 稳健的backbone, 处理多样的输入."
随后在开头和就为增加了两个不同的1x1零卷积, 初始化为零可以保证训练开始时消除随机噪声作为梯度.

如图, SD Encoder Block A包含4个残差层, 2个ViT, x3表示重复3次, 其它的看图就行.
这种结构计算效率高, 原网络冰冻没有梯度, 内存最低要求40GB, 与原sd的优化相比, 要求23%更多的内存和34%更多的训练时间.
接着讲了对输入条件的处理, 因为SD用了VQ-VAE把512x512的像素转换成64x64, 在ControlNet中对输入条件使用卷积, kernel 4x4, stride 2x2.
L=Ez0,t,ct,cf,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf)∥22]
多了个 cf, 一样是预测噪声. 50%的概率提供空text.

零卷积没有引入噪声, 网络一直可以生成精美的图片, 训练过程中发现生成与条件一致的图片是突然出现的, 大概发生在10k轮之后.
先介绍了一下sd中的Classifer-free guidance
ϵprd=ϵuc+βcfg(ϵc−ϵuc)
epsilonprd是最终输出, epsilonuc是无条件输出, epsilonc是有条件输出, betacfg是人为规定的权重. 这里表述的条件是指text.
然后ControlNet的条件可以添加到epsilonuc, 也可以添加到epsilonc, 当没有text提示词, 把COntorlNet的条件添加到epsilonuc和epsilonc可以消除Classifer-free guidance.
他们搞了个动态权重wi, ControlNet的条件图片乘以wi=64/hi, hi 是第i个block的大小, 原文后面的表述我认为有误, 我认为"h1=8, h2=16,..., h13=64"->"h1=512, h2=256,..., h13=64"
多条件同时控制. 直接相加, 没有额外的权重.
定性实验

消融实验

定量实验没啥, 指标是FID, 和其它模型比较也没啥好说的.
讨论部分讨论了 1)数据集大小, 即使1k数据集, 模型也没有崩溃, 给的样例中可以识别出狮子; 2)解释内容的能力, 很单调的线条, 生成多种不同的图片; 3) 接入社区模型, 可以直接迁移.

感受
故事性平平, 但是干货很多, 可入经典论文, zero-initialized Layers的微调策略在后面经常见到.
animate-anyone的ReferenceNet和它差不多, 但是完全换了一种解释方法.