human motion generation 的目标是生成自然, 真实, 多样的动作用于多种应用.
自回归模型, VAE编码, 归一化, GAN, DDPM, 这些技术推动了这一领域的发展, 社区对这一领域兴趣增加.
开始指出human motion generation这一任务的难点, 1)非线性由关节连接的, 受物理和生物学的限制, 2)人类大脑对不自然的运动异常敏感, 3)动作生成有条件驱动, 这就要求不仅动作本身要合理, 还需要和控制条件和谐, 4)作为非语言媒介, 要表达和控制信号一致的语义.
专注于基于文本, 语音和场景控制的人类动作生成, 不包含动作补全, 动作编辑, 动作可以通过关键点, 关节旋转, 参数化人类身体多种方式表示, 但是不包含用物理仿真环境的表示.
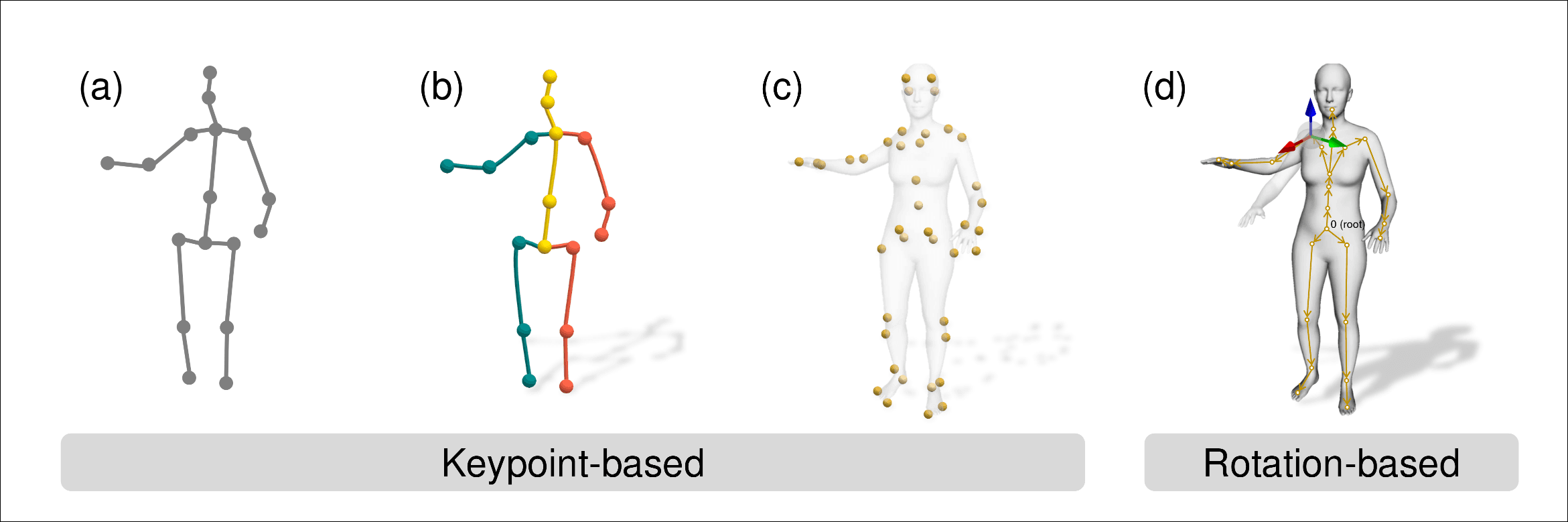
主要有两种表示方法, 基于关键点的和基于旋转角的, 图中ab是普通的表示方法, 还有通过更多的坐标拓展到c的, 游戏和动画行业多使用d基于旋转角的表示, forward kinematics(FK)和inverse kinematics(IK)可以实现两种方法的相互转换.
基于旋转角的表示是基于这样的观察: 身体各部位具有层次结构, 单一部位的旋转和层次结构中上一级有关. 旋转可以使用欧拉角, 轴角, 四元数多种方法参数化.
SMPL(Skinned Multi-Person Linear)模型通过一系列的姿势和形状参数, 可以用来生成人类motion的3D网格. 姿势参数θ∈RK×3, K=24, 即先规定根关节的位置, 然后根据层次关系依次规定各关节的旋转角, 形状参数 β∈R10指示身高等信息. 我对照上图基于关键点的表示b图数了一下, 考虑对称各关节间的连接数刚好是10个, 因此β
参数应该表示各关节间的长度信息. 输入姿势和形状信息, SMPL模型可以生成一个包含N=6890个顶点的三角网格M(θ,β)∈RN×3, 该过程可微.(总结一下, 给定位置和形状信息, SMPL可以输出N个顶点坐标, 渲染出来就是'人'的形状)

marker-based motion捕获通过在人的关键点放置标记(图a中的红色绑带)来跟踪人物移动.
markerless motion捕获不使用标记, 多个RGB或RGB-D相机在捕获过程中协同, 这种方法效果没有marker-based好, 但是更方便.
pseudo-labeling(伪标记)指使用OpenPose等动作估计方法从单眼图片或视频生成动作表示.
人工标注指人工标注:)图d展示的是MikuMikuDance的交互界面.
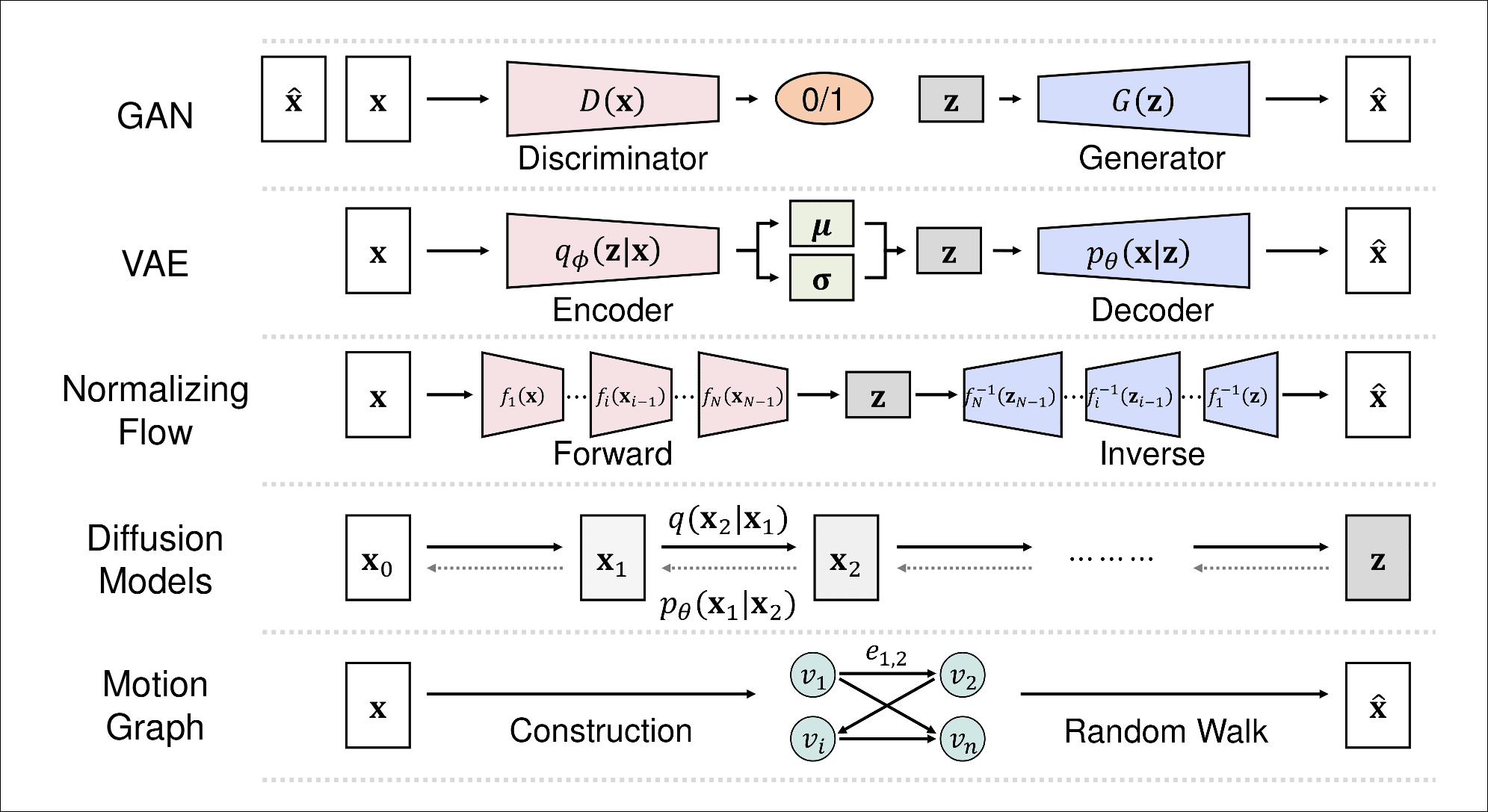
粗略可以分为两类, 基于自回归的方法和基于生成式模型的方法.
GAN网络. 一个生成器G, 一个辨别器D, G生成更逼真的图片混淆D, D准确的的区分G生成的图片和真实图片. 这种方法存在训练不稳定, 很难收敛和模式崩塌的问题.
Variational Autoencoders(VAE). 包含一个编码器一个解码器, 训练loss是ELBO(Evidence Lower Bound), 可以通过重参数化技巧提高训练效率和稳定性. 相比GAN, 存在后验崩溃的风险, 生成的样本可能不清晰.
Normalizing Flows. 目前读的论文还没见过这种方法, 开头提到GAN和VAE都隐式的学习数据的概率分布, 很难精确计算似然度, 这种方式显式的学习概率分布, 不太理解问了一下GPT, 大致含义是它的前向和后向是一个可逆的过程, 在训练过程中取真实样本x->使用反向过程映射到简单空间分布z->计算z在简单分布下的概率->计算x的似然概率并最大化,
在生成阶段, 从简单分布采样z, 使用正向过程x=f(z)生成新样本. 这种方法提供了灵活性, 精确的似然计算和简单的数据采样(so, why not Gradient Descent?笔者注), 但是需要大量的转换, 计算复杂度高, 很难训练.
扩散模型. 加噪和去噪的过程, 加噪通过一个调度器完成, 当T→∞, xT事实是高斯分布, 难在预测方向过程, 根据自己的知识可能和论文中讲述有一点不一致, 我们训练一个神经网络来预测噪声, 计算(μ,σ2), 从N(μ,σ2)
中采样作为噪声, 执行去噪. 优点训练稳定质量高, 缺点马尔科夫链多步去噪, 比VAE和GAN耗时耗资源.
动作图. 直接看上图中motion graph列, 穷举所有的动作, 用路径连接, 生成动作就是要找到一条最好的路径.
简单来说定义了一个明确的action类, 比如['Walk', 'Kick', 'Throw', ...], 用onehot编码表示, 根据action类生成对应的motion片段.
下面就介绍了GAN, latent Space, VAE, Transformer, 对比学习, 离散token表示+GPT-like, Diffusion直接预测样本, Stable Diffusion, 不同的技术.
上述这些方法只能生成单一的动作, 最近MultiAct提出了生成多动作的方法.
相对于Action to Motion从预设的action类生成motion, Text to Motion从多样的自然语言描述生成motion.
依次介绍了GAN, 文本和motion联合嵌入, VAE, Transformer.
上面的方法利用给定的数据集, 面临零样本挑战. 介绍一些方法对他的改进, 如融合文本和图片CLIP, 基于参考的运动生成方式, 文本-姿态生成器生成和文本一致的姿态掩码.
上面方法的text都很简单, 主要包含action类名, 介绍近些年的工作, 如利用VQ-VAE并行训练text-to-motion和motion-to-text, VQ-VAE+Transformer, diffusion, Transform预测序列+diffusion生成动作.(思路都是将motion离散化表示, 然后使用transform预测, 笔者注)
根据跟定的音乐生成相关的舞蹈动作, 与序列到序列的翻译一致. 介绍了一系列全监督的回归模型, 去最小化预测动作和真实动作之间的距离: LSTM, Transformer, 额外的舞者选择阶段生成多人舞蹈, global-local 动作表示. 然后指出即使是同一个音乐片段, 也会有多样的动作表示.
从生成的角度, 介绍了GAN, 音乐风格编码+改进GAN, Normalizing Flows, VQ-VAE离散化3D motion, diffusion, motion图.
生成长舞蹈存在错误积累问题, 介绍了3中方法对它的改进.
Speech to Gesture 任务旨在根据输入的语音音频, 以及在某些情况下还包括文本转录, 生成一系列人类手势, 主要应用是手语.
一些从文本转录开始的方式: GAN, motion和audio分别编码映射, 风格控制, 手势模板集, motion和audio共享表示空间, 脸部手部头部分离表示, motion分成内容和节奏段, 寻找最优motion, Transformer+diffusion.
指出人与人之间的手势会有差异, 没有同时考虑speech和转录文本模态, 介绍一些方法对它的改进: 同时考虑文本语音speaker, 情感编码, 学习speakers不同的风格, 考虑脸部表情情绪上下文含义, 建模语言和手势间的节奏和语义关系, ...
(场景生成只做了解, 简单过一下)
scene to motion任务旨在生成与场景上下文一致的合理人类动作. 场景表示方法有2D 图像, 点云, 网格, 3D 对象, 目标位置. 多阶段流程一般是预测目标位置/交互锚点->规划路径/轨迹->填充运动.
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| KIT Motion Language | Big data 2016 | Marker-based | Kpts. (3D) | 111 | 3911 | - | 10.3h | 6.3k Text descriptions |
| UESTC | MM 2018 | Markerless | Kpts. (3D) | 118 | 25.6K | - | 83h | 40 Action classes |
| NTU-RGB+D | TPAMI 2019 | Markerless | Kpts. (3D) | 106 | 114.4K | - | 74h | 120 Action classes |
| HumanAct12 | MM 2020 | Markerless | Kpts. (3D) | 12 | 1191 | 90K | 6h | 12 Action classes |
| BABEL | CVPR 2021 | Marker-based | Rot. | 344 | - | - | 43.5h | 260 Action classes |
| HumanML3D | CVPR 2022 | Marker-based & Markerless | Kpts. (3D) | 344 | 14.6K | - | 28.5h | 44.9K Text descriptions |
| TED-Gesture | CVRA 2019 | Pseudo-labeling | Kpts. (3D) | - | 1,295 | - | 52.7h | TED talks |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| Tang et al. | MM 2018 | Marker-based | Kpts. (3D) | - | 61 | 907K | 1.6h | 4 genres |
| Lee et al. | NeurIPS 2019 | Pseudo-labeling | Kpts. (2D) | - | 361K | - | 71h | 3 genres |
| Huang et al. | ICLR 2021 | Pseudo-labeling | Kpts. (2D) | - | 790 | - | 12h | 3 genres |
| AIST++ | ICCV 2021 | Markerless | Rot. | 30 | 1,408 | 10.1M | 5.2h | 10 genres |
| PMSD | TOG 2021 | Marker-based | Kpts. (3D) | 8 | - | - | 3.8h | 4 genres |
| ShaderMotion | TOG 2021 | Marker-based | Kpts. (3D) | 8 | - | - | 10.2h | 2 genres |
| Chen et al. | TOG 2021 | Manual annotation | Rot. | - | - | 160K | 9.9h | 9 genres |
| PhantomDance | AAAI 2022 | Manual annotation | Rot. | - | 260 | 795K | 3.7h | 13 genres |
| MMD-ARC | MM 2022 | Manual annotation | Rot. | - | 213 | - | 11.3h | - |
| MDC | MM 2022 | Manual annotation | Rot. | - | 798 | - | 3.5h | 2 genres |
| Aristidou et al. | TVCG 2022 | Marker-based | Rot. | 32 | - | - | 2.4h | 3 genres |
| AIOZ-GDANCE | CVPR 2023 | Pseudo-labeling | Rot. | >4000 | - | - | 16.7h | 7 dance styles, 16 music genres |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| Trinity | IVA 2018 | Pseudo-labeling | Kpts. (2D) | 1 | 23 | - | 4.1h | Casual talks |
| Speech2Gesture | CVPR 2019 | Pseudo-labeling | Kpts. (2D) | 10 | - | - | 144h | TV shows, Lectures |
| TED-Gesture++ | TOG 2020 | Pseudo-labeling | Kpts. (3D) | - | 1,766 | - | 97.0h | Extension of TED-Gesture |
| PATS | ECCV 2020 | Pseudo-labeling | Kpts. (2D) | 25 | - | - | 251h | Extension of Speech2Gesture |
| Speech2Gesture-3D | IVA 2021 | Pseudo-labeling | Kpts. (3D) | 6 | - | - | 33h | Videos from Speech2Gesture |
| SHOW | CVPR 2023 | Pseudo-labeling | Rot. | - | - | - | 27h | Videos from Speech2Gesture |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| BEAT | ECCV 2022 | Marker-based | Rot. | 30 | 2508 | 30M | 76h | 8 emotions, 4 languages |
| Chinese Gesture | TOG 2022 | Marker-based | Rot. | 5 | - | - | 4h | Chinese |
| ZEGGS | CGF 2023 | Marker-based | Rot. | 1 | 67 | - | 2.3h | 19 Styles |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| WBHM | ICAR 2015 | Marker-based | Rot. | 43 | 3704 | 691K | 7.68h | 41 objects |
| PiGraph | TOG 2016 | Markerless | Kpts. (3D) | 5 | 63 | 0.1M | 2h | 30 scenes, 19 objects |
| PROX | ICCV 2019 | Markerless | Rot. | 20 | 60 | 0.1M | 1h | 12 indoor scenes |
| 3DB | SIGGRAPH 2019 | Pseudo-labeling | Kpts. (3D) | 1 | - | - | - | 15 scenes |
| SAMP | ICCV 2021 | Marker-based | Rot. | 1 | - | 185K | 0.83h | 7 objects |
| COUCH | ECCV 2022 | Marker-based | Rot. | 6 | >500 | - | 3h | 3 chairs, hand interaction on chairs |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| GTA-IM | ECCV 2020 | Marker-based | Kpts. (3D) | 50 | 119 | 1M | - | Synthetic, 10 indoor scenes |
| GRAB | ECCV 2020 | Marker-based | Rot. | 10 | 1334 | 1.6M | - | 51 objects |
| HPS | CVPR 2021 | Marker-based | Rot. | 7 | - | 300K | - | 8 large scenes, some > 1000 m² |
| HUMANISE | NeurIPS 2022 | Marker-based | Rot. | - | 19.6K | 1.2M | - | 643 scenes |
| CIRCLE | CVPR 2023 | Marker-based | Rot. | 5 | >7K | 4.3M | 10h | 9 scenes |
| Name | Venue | Collection | Representation | Subjects | Sequences | Frames | Length | Remarks |
|---|
| Human3.6M | TPAMI 2014 | Marker-based | Kpts. (3D) | 11 | - | 3.6M | 5.0h | 15 actions |
| CMU Mocap | Online 2015 | Marker-based | Rot. | 109 | 2605 | - | 9h | 6 categories, 23 subcategories |
| AMASS | ICCV 2019 | Marker-based | Rot. | 344 | 11265 | - | 40.0h | Unifies 15 marker-based MoCap datasets |
| HuMMan | ECCV 2022 | Markerless | Rot. | 1000 | 400K | 60M | - | 500 actions |
| Category | Subcategory | Metric |
|---|
| Fidelity | Comparison with Ground-truth | Distance |
| | Accuracy |
| Naturalness | Motion space |
| | Feature space |
| Physical Plausibility | Foot sliding |
| | Foot-ground contact |
| Diversity | Intra-motion | Variation |
| | Freezing rate |
| Inter-motion | Coverage |
| | Multi-modality |
| Condition Consistency | Text-Motion | Accuracy |
| | Distance |
| Audio-Motion | Beat |
| | Semantics |
| Scene-Motion | Non-collision score |
| | Human-scene contact |
| User Study | Subjective Evaluation | Preference |
| | Rating |