Cross-identity Video Motion Retargeting with Joint Transformation and Synthesis
提出了一种双分支转换合成网络, 用于视频位置重定向, 输入是一段subject视频, 一段motion 驱动的视频, 输出是一段视频, 有subject的外观和驱动视频的动作模式. TS-Net包括基于变形的转换分支和无变形的合成分支, 双重设计结合了基于变形网格的转换和无变形生成的优点, 提高了身份保持和合成视频中遮挡的鲁棒性.

介绍
讲任务: Motion retargeting旨在将驱动视频中的动作转移到目标视频中, 同时保持目标视频主体的身份. 图像领域的运动重定向已被广泛探索, 视频相对动作的难点在于保持时间的连续性.
讲先前工作, 突出两个信息, 基于扭曲的合成可以更好地保持身份, 而无扭曲生成有助于产生新像素.
Transformation-Synthesis Network, 简称TS-Net 融合了先前工作的这两个优点, 提出的变换分支通过将规则网格与驱动掩码特征和主体图像特征之间的空间相似性矩阵加权来计算变形流. 同时设计了一种掩码感知的相似性方法, 以避免比较特征图中的所有点对.
相关工作
引导图片生成
集中在特定条件的引导生成任务上, 例如姿态引导的人像生成和面部表情生成. 接着详细讲了一下这两种任务和代表的方法. 最近一下方法开始探索通用引导图像生成, 指出了一些代表作.
video motion retarget
由于在时间维度上增加了连贯性要求而更具挑战性. 这里的叙述思路是"提一句先前的方法->相比之下TS-Net有什么优势". 多数方法集中在特定领域, 人体姿态运动重定向或面部表情重定向, TS-Net各领域都表现好; 最近的方法基于最先进的具有U-Net结构和AdaIN模块的生成器, TS-Net使用一个更稳健且通用的GAN生成器; 先前的工作通过结合基于变形和无变形生成来进行视频运动重定向, 他们的变形流总是应用于先前生成的帧, 可能导致合成伪影的累积, TS-Net则在特征空间中计算驱动掩码和真实主体图像之间的变形流以避免这个问题.
方法
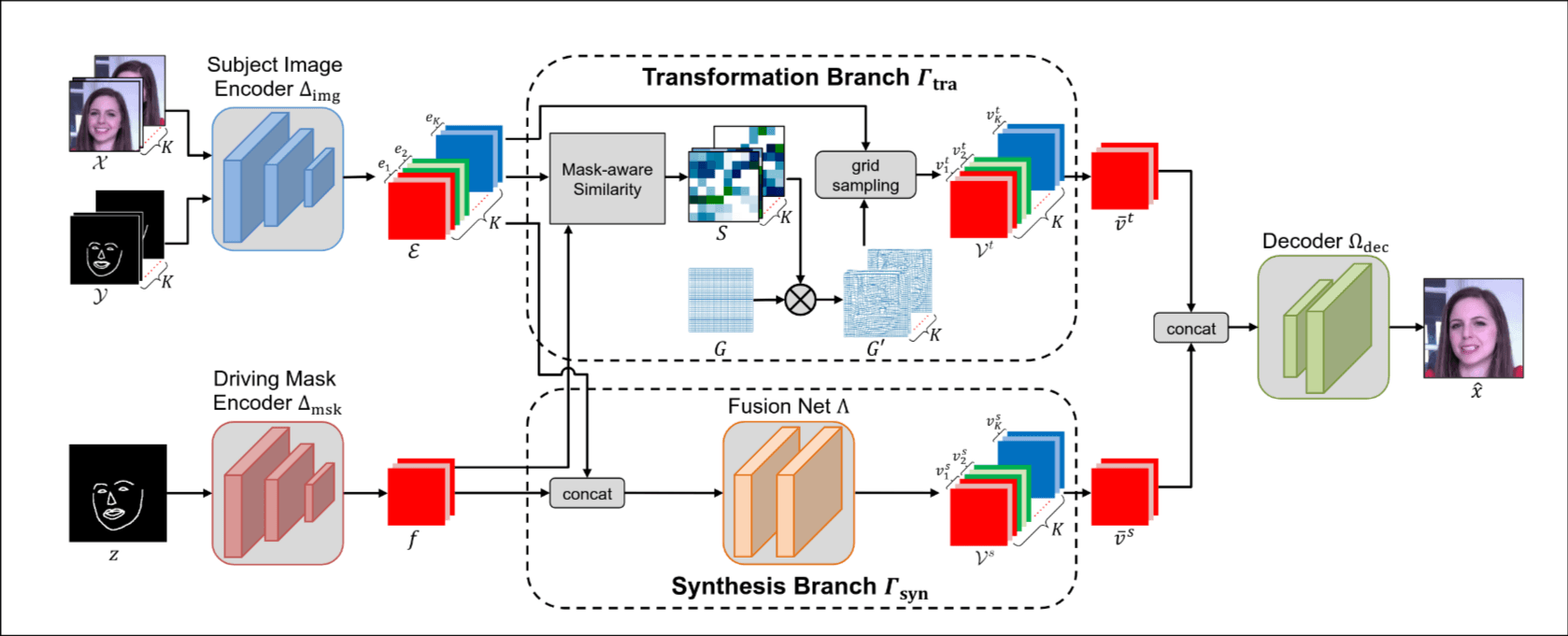
模型结构
在理解模型结构前有一个重要的概念叫做deformation flow, 它是一种特征空间的扭曲场, 表示驱动视频掩码特征与主体视频帧特征之间的空间对应关系, 它不直接扭曲像素, 而是扭曲低维特征图, 计算效率高且能处理大运动和遮挡问题.
输入是subject视频帧序列, subject掩码序列, 驱动掩码帧, 掩码的生成方式是使用预训练的2D稀疏关键点检测器, 如Dlib用于人脸, OpenPose用于人体姿态.
Transformation 分支
基于deformation flow进行warp-based transformation.
核心机制是计算驱动视频掩码特征与主体视频帧特征之间的cosine similarity matrix, 利用该矩阵加权regular grid, 生成sampling grids, 用于扭曲主体特征. 通过多帧特征平均得到最终扭曲特征.
优势是通过多对应点计算缓解遮挡问题, 处理大运动更鲁棒; 引入掩码感知相似性计算降低计算开销.
合成分支
直接进行特征融合与合成.
核心机制是将主体帧特征与驱动掩码特征拼接, 通过全卷积融合网络生成合成特征图, 多帧特征平均后得到最终合成特征.
最后将了一下优势, 避免依赖像素级对应关系, 可生成新像素(如遮挡区域), 减少身份泄露.
分支协作
将两个分支的输出特征 和 直接拼接, 输入解码器生成最终视频帧.
训练和推理
这里主要是介绍了各种各样的损失函数, 使用对抗损失, 感知损失, 特征匹配损失和变换分支损失进行训练, 确保生成的视频在视觉上真实且保持身份信息.
实验
人脸视频来自FaceForensics, 150条训练集150条测试集, 使用Dlib检测68个面部关键点; 舞蹈跳舞数据集来自youtube, 100条训练集, 85条测试集, 使用OpenPose提取.
评估指标上, 自重建任务: 同一段视频分成两段, 一段作为subject视频, 一段作为驱动视频, 指标是归一化L1距离和LPIPS. 跨身份迁移任务, subject视频和驱动视频来自不同的人, 指标来自用户评估.
讲了一下模型结构的具体细节.
在面部和舞蹈数据集上的实验结果表明, TS-Net在视频运动重定向方面优于几种最先进的模型以及其单分支变体.
局限
依赖于现成的检测器生成的掩码; 高频细节的合成; 潜在的社会负面影响.
感受
它的大致思路就是pose姿态和subject细节分开处理, 故事讲的稀烂, 评估做得很浅, 训练数据集也太少了, 中间有个deformation flow还不是很理解, 读到这个程度就行了吧.