Audio-visual Controlled Video Diffusion with Masked Selective State Spaces Modeling for Natural Talking Head Generation
讲特点: 支持多信号控制的Talking head generation. 讲方法: 平行多分支, 门控机制, mamba structure保证时间和空间连续性, mask-drop策略.

介绍
Talking Head Generation旨在生成由特殊信号驱动的逼真的肖像视频, audio和facial motion是两种常见的信号.
大多数方法只使用单一的控制信号, 一些工作开始研究统一的框架, 但是在推理阶段依然之允许一种控制信号.
讲难点: 1)audio主要影响嘴部区域, facial motion可以准确影响脸部表达, 直接应用两种信号会出现冲突. 2) 当前的diffusion模型倾向于时间和空间连续性分阶段处理, 会忽略时间维度和空间维度的相互作用, 另外当控制信号和spatio-temporal feature集合时, attention map变得很大, 影响效率.
讲方法, 提出ACTalker, 一个端到端框架, 集成了spatio-temporal feature, 多种控制信号的photo-realisic Talking Head Generation, 具体方法后面看.
后面讲的实验结果和贡献总结.
相关工作
Talking Head Generation
分两个派系, non-diffusion-based和diffusion-based. non-diffusion-based以逼真的人脸和高保真度闻名, 使用Taylor估计评估两个脸的距离, 使用wrap, 或将audio映射到spatial expression landmarks, 遵循expression-driven方式的流程; 随着diffusion方法的发展, 讲到了stable diffusion和motion module等等方法.
然后提到大部分方法只使用一种控制信号, 他们使用两种, 且使用mamba structure来增强模型同步学习时间和空间的能力.
Selective State Space Models
这里应该和它具体使用的方法有关, 没讲SSM是什么, 还有一堆没见过的缩写, 读不懂, 但是可以确定通过使用SSM可以集成多种控制条件, 同时学习时间和空间信息.
方法
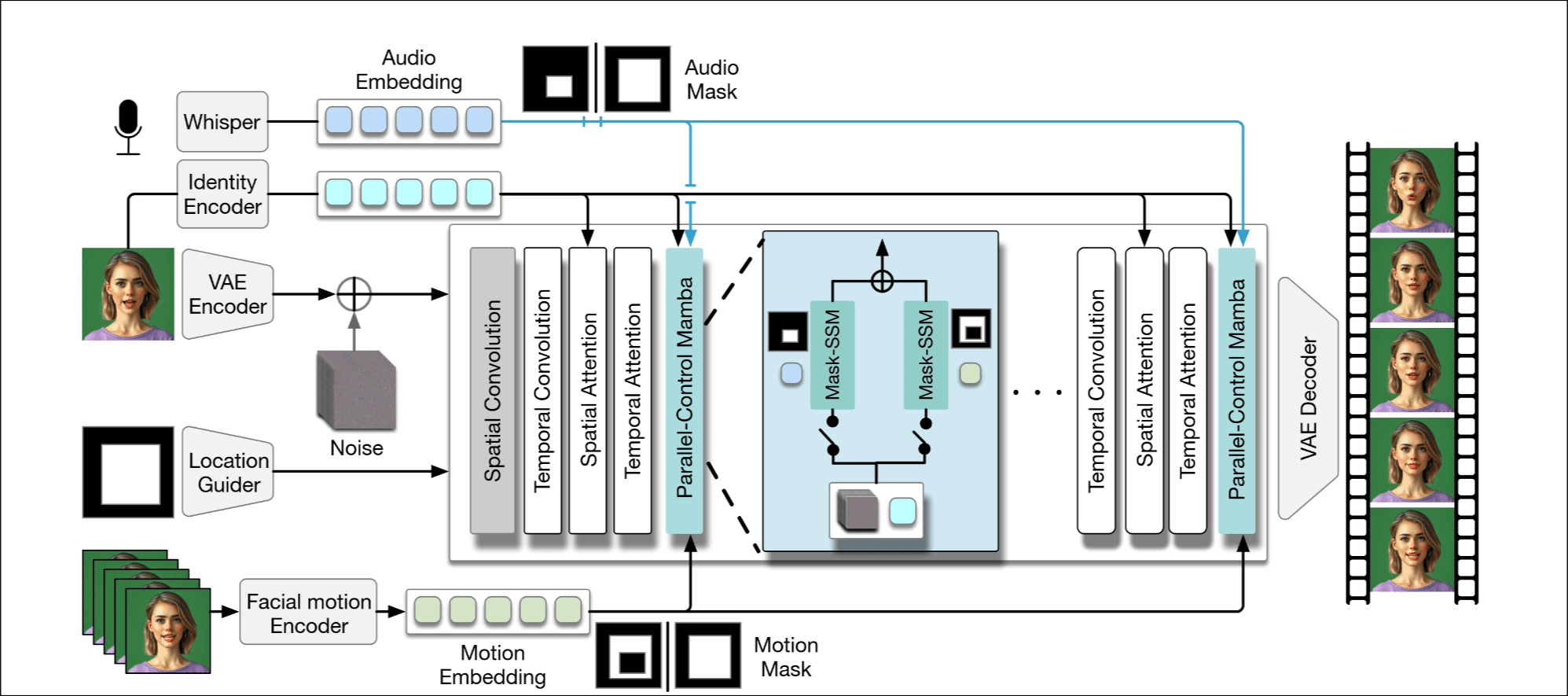
overview
SVD作为codebase, 输入条件有源图片, face mask , facial motion sequences , audio segment . AVE提取, Whisper提取, pretrained motion encoder提取隐式面部动作, identity encoder从获取identity embed.
在每个block设计了 parallel-control mamba Layer(PCM), 实现多信号控制, 具体后面会讲.
Parallel-control Mamba Layer
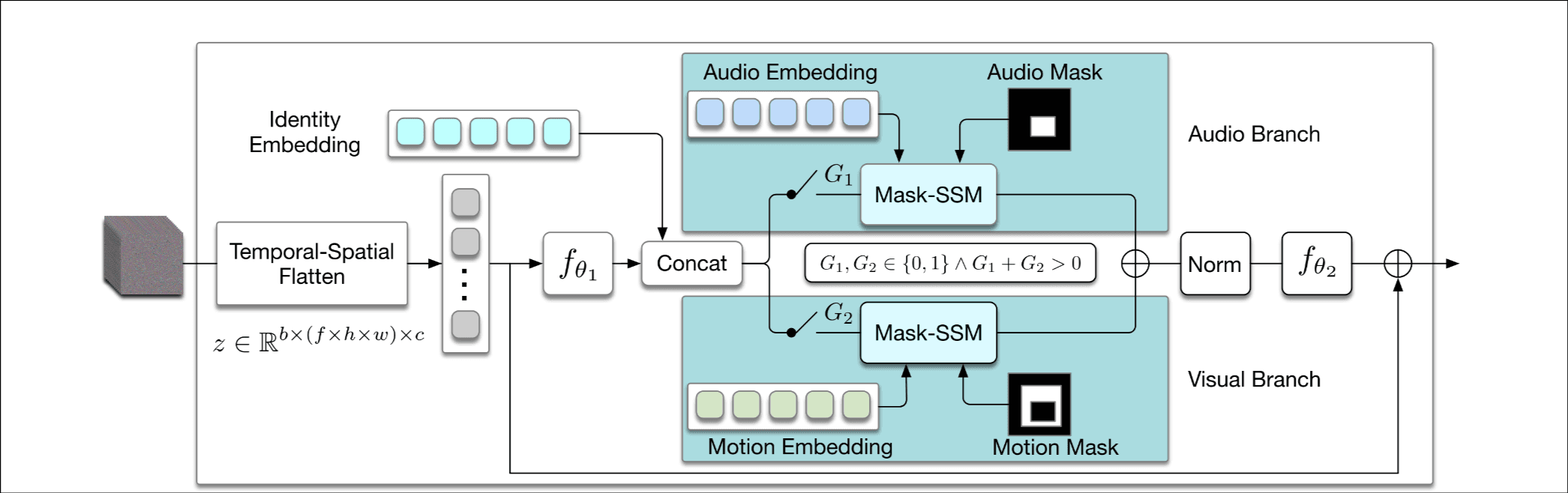
首先介绍了一下pcm, 看上图很好理解.
然后详细讲了左边concat操作那里, 是一个MLP, 保证维度和identity embedding相同, 方便和其他embedding interact.
读者注
这样效果真的好吗, 信息被极度的压缩, UNET有这种操作, 先压缩后还原, 但是人家还有残差连接稳定训练. 另外这样搞视频长度和大小不可变了吧.
中间的gate门控机制就不介绍了, 很好理解.
右边的连接, 过norm稳定训练, 同样是MLP还原到原shape.
Mask-SSM
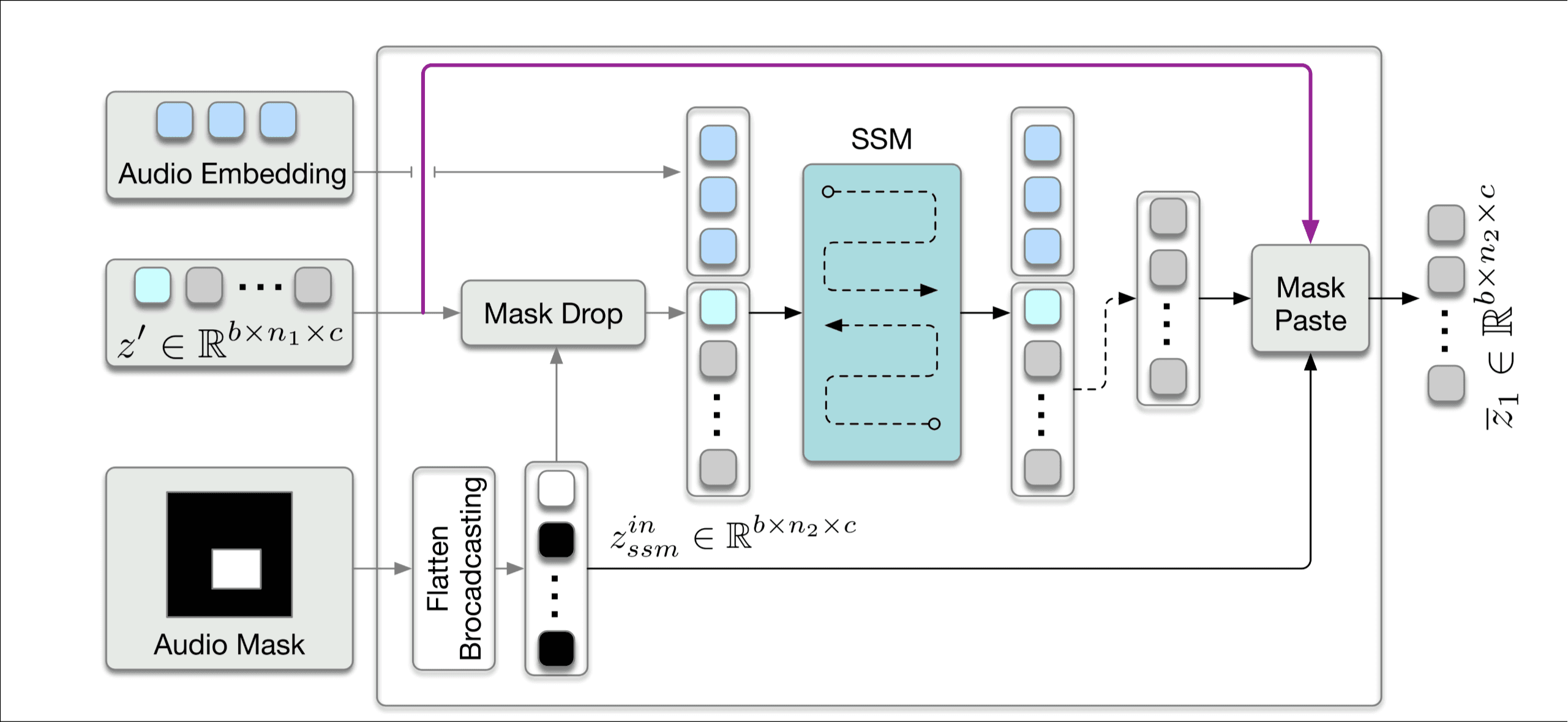
这里它讲了 (frames × width × height) 非常大, 为了高效训练才使用MLP映射到低维的. 为了防止条件冲突, 设计的mask可以让不同的信号控制不同的区域.
首先要搞清楚SSM操作, 但是我不打算深究, 只需要知道输入和输出的shape一致, 可以促进token间的交互就行, 像self attention一样.
照着图叙述一遍流程, concat操作后得到, 通过mask drop其中不需要关注的mask, 剩下的token和audio拼接后过SSM, 取结果中非audio嵌入部分, 再加上在mask drop中去除的token.
训练和推理
没什么特别的
z是训练样本的latent embedding, C是条件设置, 在推理阶段要手动设置门控, 就图中的, 只要内存足够, 可以生成任意长度的视频.
实验
没什么有用的信息.
感受
最大的困惑是在推理阶段支持audio和facial motion两种控制信号有什么意义吗, 专注于做audio control或facial motion control有什么问题吗, 技术不能脱离实际应用呀.