TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models
讲任务: 把预训练的视频生成模型, 转换为由音乐驱动的角色动画化. 讲方法: 通过在视频生成基础模型中集成一个audio LLM实现自然对话的经历. 讲贡献: 1) 把一个预训练的image-to-video SOTA模型改造成了一个音频驱动的头像生成模型; 2)无限视频流, 无错误累计, 通过蒸馏技术; 3) 高吞吐, 低延时的推理管道.
介绍
文生视频, 图生视频蓬勃发展, 指出实时的交互应用面临挑战. 主要限制是双向注意力机制, 要求一次生成整个视频序列, 每一独一帧依赖于未来的帧.
提出TalkingMachines方法, 将预训练的双向视频diffuison模型转换为高效的自回归系统. 讲贡献, 1)改动预训练的视频模型, 通过特殊的注意力机制和训练策略, 支持音频驱动的生成; 2) 无限长度的生成, 通过改造的Distribution Matching Distillation(DMD), 可以自回归生成, 没有累计误差; 3)实时的表现, 蒸馏模型到两个时间步, 系统级的优化.
背景
Flow Matching Models
使用预训练的WAN2.1模型, audio作为额外的控制信号.
与传统的随机diffusion对比, flow matching更加稳定高效, 通过速度场在latent space中建立确定的轨迹. 不同于随机微分方程, flow matching将生成看作常微分方程积分问题.
rectified flow之前有一篇读到过, 哦对MMaudio这篇, 直接取高斯噪声, 真实值是, 那么对于时间步
真实值的速度场
条件是文本嵌入, 音频嵌入和图片嵌入, 模型的任务是预测速度场:
Distribution Matching Distillation
翻译过来应该是分布匹配蒸馏, 它解决了多步采样的问题, 通过训练高效的few-step generator, 与传统的保留单个采样轨迹的蒸馏方法不同, DMD在分布层面运作, 使得学生模型设计具有更大的灵活性.
首先解释一个概念叫做reverse KL divergence, 他用于衡量学生生成器分布和数据分布之间的差异.
DMD的目标就是让一个few-step的学生模型学会逼近一个多步的教师模型分布, 从而加速采样.
相关工作
视频基础模型
diffuison, 特别是DiT推动的视频生成的发展, 但是SOTA模型主要设计用于offline生成, 这些模型使用了双向注意力结构, 虽然有利于维护生成质量和时间连续性, 妨碍了实时流的应用.
Audio-Driven Animation
3D morphable model -> GAN -> diffuison-base. 高延迟和风格有限. 本模型解决了实际应用的局限性.
Real-time Talking Head Generation
常规: 使用外表提取器提取静态生成特征, motion提取器表示面部动态表示低维时间序列, 通常是一维向量. 在推理阶段, 一个轻量的生成模型更与audio预测motion序列, 然后和静态外表嵌入联合实时生成.
more
这里要多说两句. 在阅读的上一篇平平无奇的论文TSNet, 相关工作的一句话中我了解到引导图片生成中有两个很火的研究领域, 姿态引导的人像生成和面部表情生成, 其实更早, 读到animate anyone时, 它就是有两个功能, 一个是通过面部关键点控制, 一个通过pose姿态控制, 当时我只关注了pose生成, 其实面部控制又延伸了新的研究方向, 就是这里介绍的Real-time Talking Head Generation, 关注实时性, 且他们已经摆脱了提取面部关键点这一步!
而music to dance, 任务本质和Talking Head Generation很接近, 只是pose会复杂一点, 但是我到目前为止没有读到人们对这领域的探索.
我认为原因有:
-
没有摆脱music和pose之间的强绑定. 深入分析原因, AIST++作为music dance任务的权威数据集, 与music dance任务强绑定, AIST++又与pose的表示方式强绑定, 研究围绕AIST++展开, 给人music dance与pose强绑定的刻板印象.
-
music to dance任务的常见评估指标, 突出专业性, 忽略了美学性质和真实世界的实际应用, 实际23年发表的POPDG, 25年发表的x-dancer, 都在尝试突破这个AIST++这个屏障, POPDG创建了更美学的数据集, x-dancer应用网络上广泛的单眼2D视频, 不彻底. 甚至有点好笑的的是一篇21年的dance any beat, 已经认识到了pose的缺陷, 改为使用视频输入, 但是它的视频还是来自AIST++! (这里可以提一下数据集的限制)
-
music to dance任务被低估了, 研究的人不多, 主流认为在辅助编舞, 更多的会提一下提升AR体验, music to dance video应该有更多的应用.
-
技术的限制. 21, 22年diffusion技术不如现在成熟, SMPL的表示方法更容易出效果.
-
换了个教室上课, 忘记了, 记起来再写.
降温
提出问题是一回事, 解决问题是另一回事. 这也是为什么要持续阅读论文.
上面提到的方法计算十分高效, 可以在消费级GPU上实现实时生成, 无需额外的优化, 但是内在结构限制了通用性, 依赖rigid and non-rigid 3D warping为面部特制, 无法拓展到全身. 另外motion 表示的compactness, 限制了模型捕获超越头和面部动态的能力.
本论文的方法探索了大尺度Diffusion Transformer的使用, 为了满足实时需求, 实现了稀疏因果注意力和工程优化.
模型蒸馏
没什么有用信息, 加速diffusion推理大成功.
方法
模型结构
基模型是WAN2.1, 14B参数的I2V模型, 支持图片和文本提示词.
带注意力掩码的交叉注意力. 修改了cross attention层支持音频输入, 基本上在每一个cross attention层, 初始化新的层来从输入的音频标记生成键和值, 然后这些键和值与相应潜在帧标记的查询进行交叉注意力(周一师兄提到的一个cross attention的点当时没理解, 可能就是这个). 还用了一个掩码机制让audio只关注面部区域.
音频映射层. 一个1.2B参数的音频模块处理原始音频嵌入, 在送入cross attention之前. audio token和视频帧是对齐的, 每个潜在帧只会关注自身和相邻5帧的token. 然后叙述考虑到speech驱动的motion主要被temporally local audio features影响, 这个localized注意力帮助模型更好的理解audio-visual关系.
speaking/slience mode. 在slience mode使用零嵌入. 对于有多人的情况, 使用一个lipsyncing评估模型选择得分最高的切换为speaking模式, 其他保持slience模式. 在推理阶段, 通过特殊的音频嵌入(零嵌入)保持slience模式, 同时可能支持多个角色(这整段怎么一股ai味).
Asymmetric Distillation with Modified CausVid
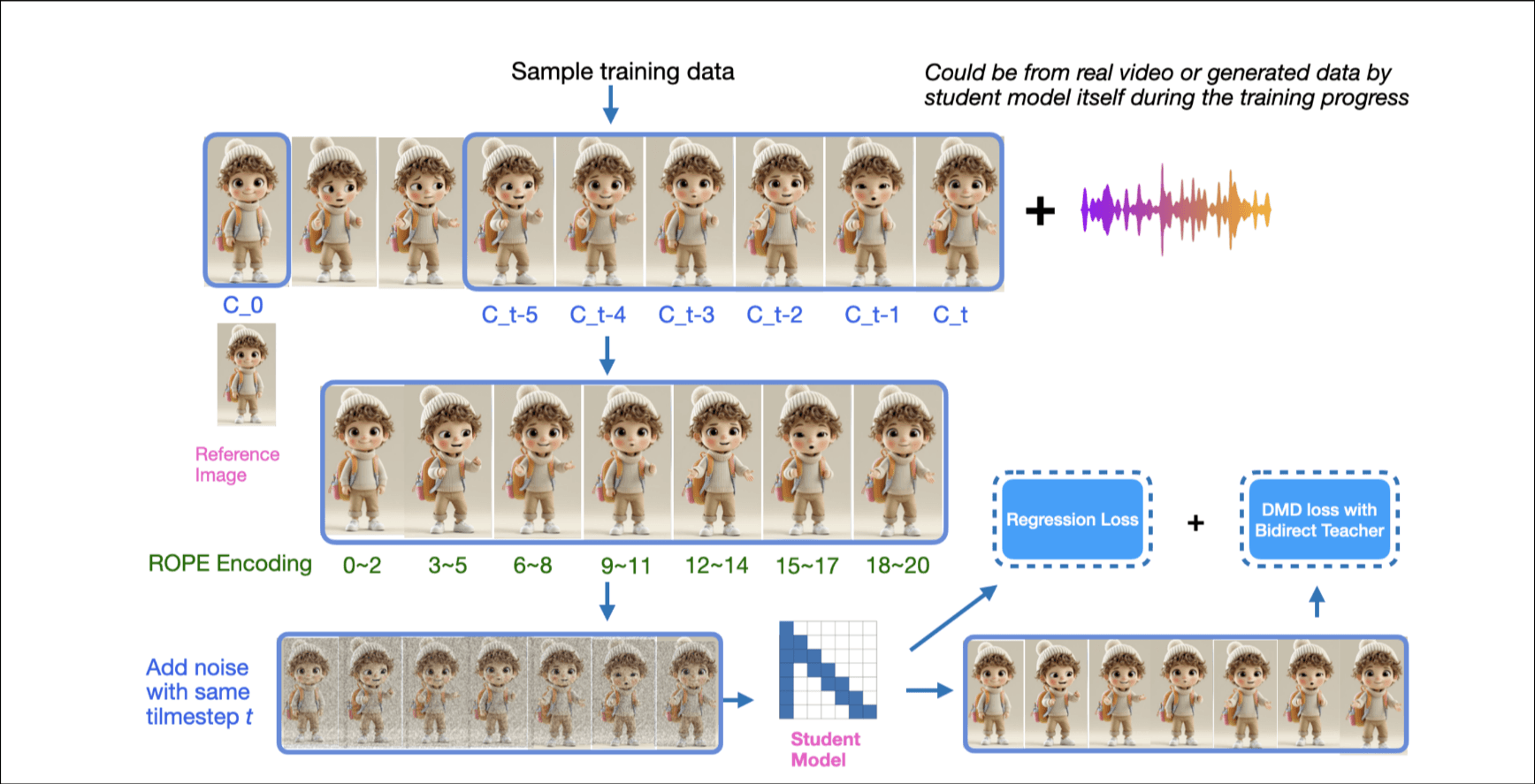
这一小节蒸馏的工作. 基于CausVid框架的改进, 为了减小首帧延迟, 减小context长度到更小的chunk, 在chunk中维持注意力.
下面讲了几点自己的方法和CausVid的不同. 1)同步不同chunk的时间步; 2)speech-drive的motion只需要小的注意力窗口, 设计稀疏因果注意力掩码. 它的视频VAE编码后从81帧变成了21帧, 有研究的价值.
使用DMD蒸馏模型, NFE(Number of Function Evaluations)从24(12 x 2 with CFG, CFG要运行正向和反向两次)降到2. 关键修改: 1) 混合真实样本和训练生成的样本; 2) Sparse Causal Attention. 只关注当前帧和相邻的一帧; 3) Regression Loss without GAN.(这哥们包使用了LLM辅助撰写)
系统优化
介绍 TalkingMachines 中的系统优化, 包括 Score-VAE 解耦, CUDA 流和 KV & 嵌入缓存.
实验
介绍 TalkingMachines 使用的训练数据集; 介绍 TalkingMachines 的训练设置和策略; 介绍 TalkingMachines 的训练基础设施和内存优化策略; 分析不同蒸馏配置对性能的影响.
应用
系统结构: 1) audio LLM集成; 2) 视频生成服务器; 3) WebRTC 流.
系统通过分布式管道运行, 用户音频通过网络界面捕获, 由音频大模型处理以生成对话响应, 并转发到我们的视频生成服务器. 生成的视频帧与音频同步, 并通过WebRTC服务流回客户端, 实现与AI生成的虚拟形象进行实时互动对话.
感受
与之前读的字节的Seedweed-7B一样输入技术综述类文章, 这类文章有个特点使用的技术一定是最新的, 面向实际应用的. 言简意骇读起来很舒服, 信息量很大, 很多地方我都是直接翻译.
想说的感受在上一个callout说完了.