EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
讲任务: Talking Head video Generation, 专注于音频提示和面部表达微妙关系. 讲方法: 端到端生成, 不需要3D建模, 保证时间连续和身份保持.

介绍
diffusion变革了生成模型, image -> video -> human-centric video(人像视频生成, 人类动画化). Talking Head video的任务是输入音频数据, 输出头部视频, 节奏与音频同步, 时间连续, 身份对齐.
介绍挑战: 音频, 视频的一对多对应关系, 大部分方法用3D建模, 做video to video转换, 这样会丢失与speaker联系的微妙表情, 因此它们想直接用diffusion的生成能力.
讲方法: 1) 拓展stable diffusion, 增加了时间层和三维卷积; 2) audio feature extractor 和 audio attention; 3)Face Locator and Speed Layers, 在身份保持上做了一些改进.
讲结果: 250小时的音频数据用于训练, 多语言. 提出新指标, 达到SOTA效果.
相关工作
Diffusion Model
在图片生成, 图片编辑, 视频生成, 3D内容生成. SD是一个代表, 使用text-image数据集训练. 最近的工作应用时间层和3D卷积支持更大尺度的数据和参数量.
Audio-driven talking head generation
分为基于视频的方法和基础图片的方法. 基于视频的方法在一个输入视频上编辑嘴唇的移动; 基于单图片的方法, 生成与参考图片形象保持一致的视频, 通常先生成头部动作和面部表达, 然后用他渲染视频的生成. 指出通性问题, 3D mesh限制了表示能力, non-diffusion的方法(先生成3DMM) 限制了生成结果的表现.
方法
初步准备
SD的一些概念.
Network Pipelines
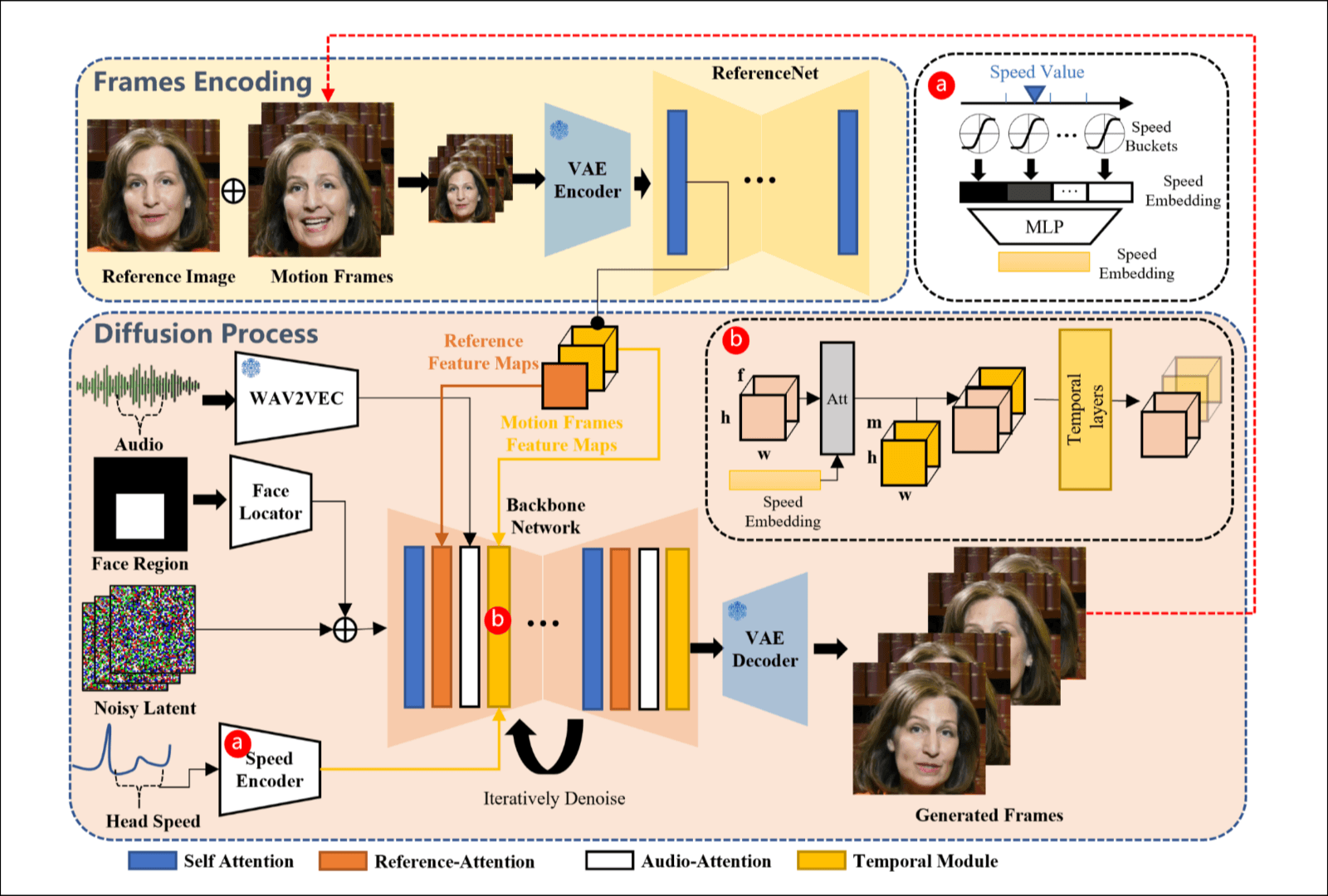
这篇论文是根据SD1.5(文生图)改的, 结合上图介绍它的改动.
- 提示词嵌入没有了, 把对用的cross attention层改成了reference-attention layers. 实现和Animate anyone基本一致, 有一点区别, 输入除了参考图片还有Motion Frames, 看起来是生成的前N帧信息一起过ReferenceNet, 输入主去噪网络的还是Reference Image对应时间维度的输出(这里的Motion Frames不影响reference-attention layer的结果, 帧间无交流, 提一些后面还要讲Motion Frames罢了).
- 增加了Audio Attention, 音频提取是每帧音频对应一维表示. 每一帧的表示和前后n帧的表示拼接到一起, 做自注意力.
- 时间层除了说reshape, 它还想保留前N帧的信息, 它让前N帧过ReferenceNet, 结果和时间层的前一层结果拼接到一起过时间层.
- 有一个face region, 用掩码表示, 过一个轻量的卷积(Face Locator)后与Noisy融合.
- 我认为可以单独命名一个headSpeed-attention, 但是它放到了时间层里讲, 速度特征表示头部的转动速度, 怎么提取就先不管, , 后面要在f维度做交叉注意力, , 可以推断每一帧速度特征的表示, 过一个MLP后reshape为, 可以当作text嵌入处理. 多补充一点, 因为这里text嵌入怎么做我其实并不清楚, 将F广播到, 与去噪网络中的shape输入一致, 之后在f维度做cross attention.
注意
关于4和5, 有一个疑问, 难道它引入了位置掩码和面部转动速度信息吗, 确实是这样, 他们自己标注了一部分数据集. "准确估计用于数据集标注的人头旋转速度存在难度, 这意味着预测的速度序列本质上是嘈杂的."
训练策略
第一阶段图片预训练, 训练ReferenceNet和Face Locator; 第二阶段使用视频, 训练时间层和audio attention; 第三阶段训练时间层和速度层.
估计他们完成前两阶段训练后效果不好又补充了第三阶段.
实验
实现
250小时的视频数据, 多数据集拼接. 头部旋转速度通过使用面部特征点提取每一帧的6自由度头部姿态, 然后计算帧间的旋转角度来标记.
image size为512 x 512, 第一阶段batch size为48; 二三阶段视频长度为12, Motion Frames长度为4, batch size为4, m设置为2, 训练速度15秒一个batch.(几篇论文给的音频控制信号长度都很短)
后面就多个算法比较, 定量评估, 消融实验比较了Speed Layer和Face Locator的影响.(侧向反映了这两处为原创而非拼接)
感受
发现很多做这类工作的人以前都是做3D的.
这个故事围绕一个核心点, 使用3D建模信号控制生成的Talking Head video丢失了speaker微妙的情感信息, 直接将音频控制信号输入diffusion可以保留这种信息.
为了保留前N帧的信息, 做长视频生成, 它让前N帧的输出过ReferenceNet, 感觉是有问题的, ReferenceNet提取的是空间信息, 理想情况下是不保留motion信息的, 而我们输入前N帧想要的肯定是motion信息, 凭直觉Hallo3处理长视频生成的方法更好.