Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Video Diffusion Transformer
讲难点: 肖像图像动画化面临困难, 特别在处理非正面视角, 渲染动态视角, 生成沉浸式, 逼真的背景. 讲贡献: 第一个利用transformer-base预训练视频生成大模型解决上述问题. 讲方法: 1) identity reference network确保面部特征连续性; 2) 研究了多种音频条件和运动帧的机制.

介绍
讲任务: portrait image animation 涉及处理生成实时面部表达, 嘴唇移动, 头部pose流程, 基于portrait image. 应用广泛, 研究的人很多.
讲历史: 利用facial landmarks(key points)与三维参数化模型[受到重建精度, 结果表达精度的限制] -> GAN, Diffusion, 可以实现高分辨率, 高质量面部细节, 长时间保持 -> 一些最新的方法.
讲限制: 1) 非正面图像生成存在困难; 2) 头部配饰保持; 3) 动态背景生成困难.
讲成就: 首次将transformer-base预训练模型引入portrait image animation任务, 在身份保持, speech audio conditionVideo extrapolation三个方面提出了自己的方案.
讲评估.
方法
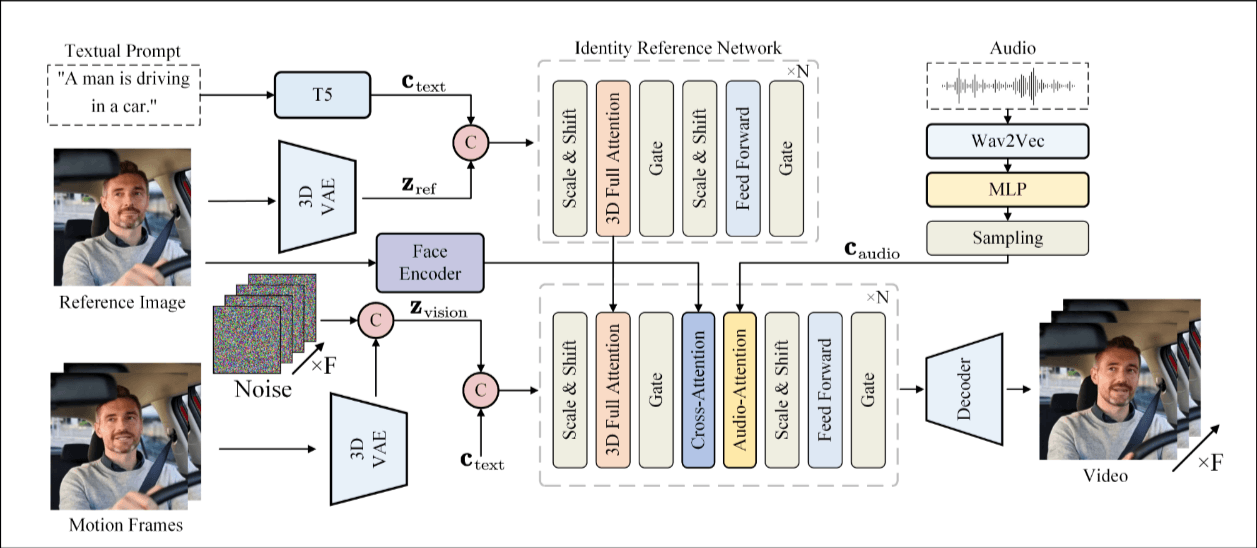
Baseline Transformer Diffusion Network
Baseline Network. 基础模型是CogVideoX, 使用3D VAE压缩视频, 使用T5压缩文本. 为了处理文本和视频的discrepancies(差异?), 使用了一个adaptive layer normalization techniques. 3D RoPE被用来捕获帧间关系.
Conditioning in Diffusion Transformer. 增加了身份条件和音频条件. 总结了在diffusion中主要的4种条件注入方式, in-context conditioning, cross attention, adaLN, adaLN-zero. 然后说本论文主要用cross attention(条件作为k, v, latent 表示作为q)和adaLN(只适用于简单条件)这两种.
audio驱动Transformer diffusion
speech audio 嵌入. 使用wav2vec提取音频特征, 为了帧对齐, 用了3个线性层(MLP).
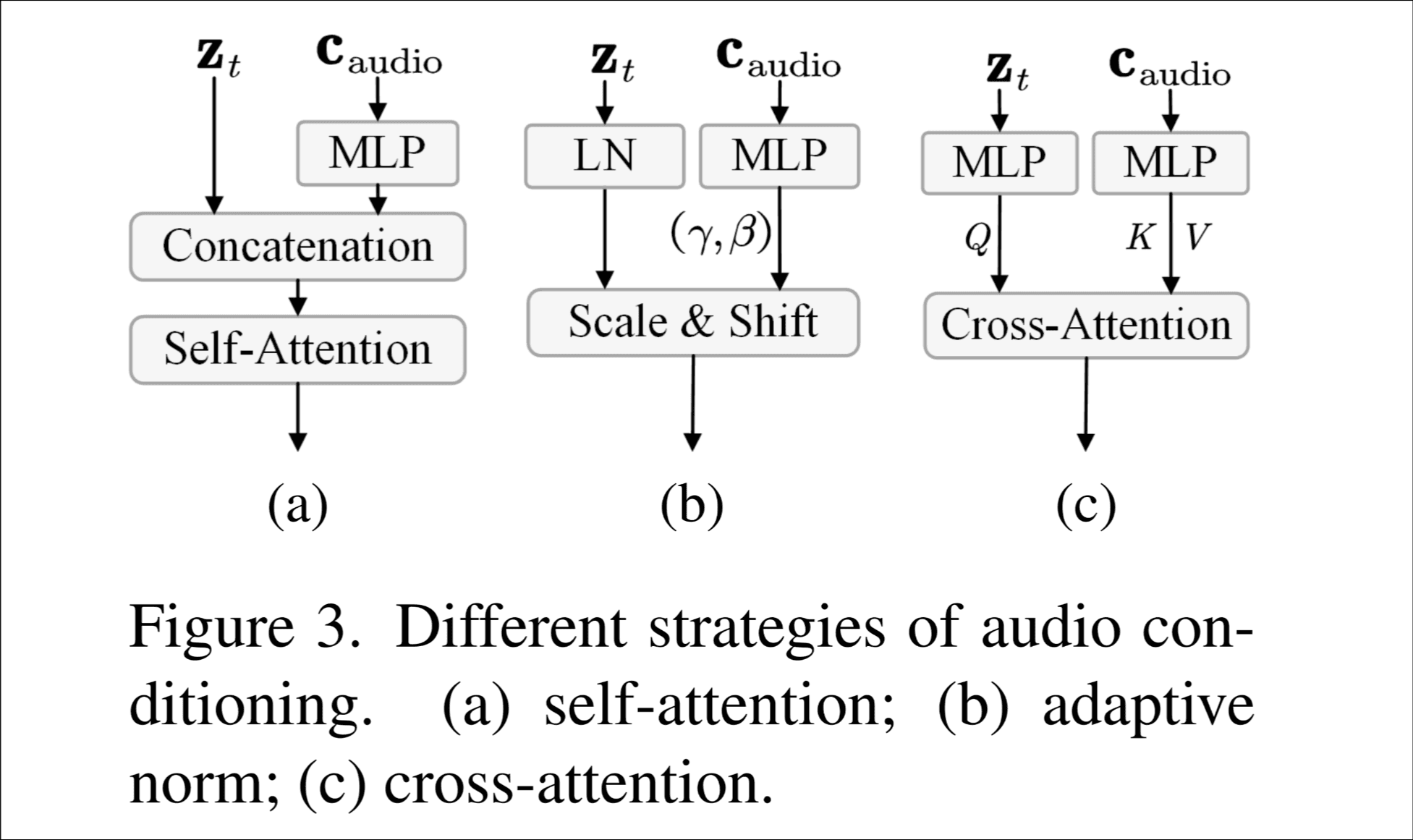
speech audio条件注入. 他们尝试了3种方案, self-attention, adaptive normalization和 cross attention, 最后发现cross attention的效果最好, 这里三种方案是怎么实现的值得学习, 我把图放在下面.
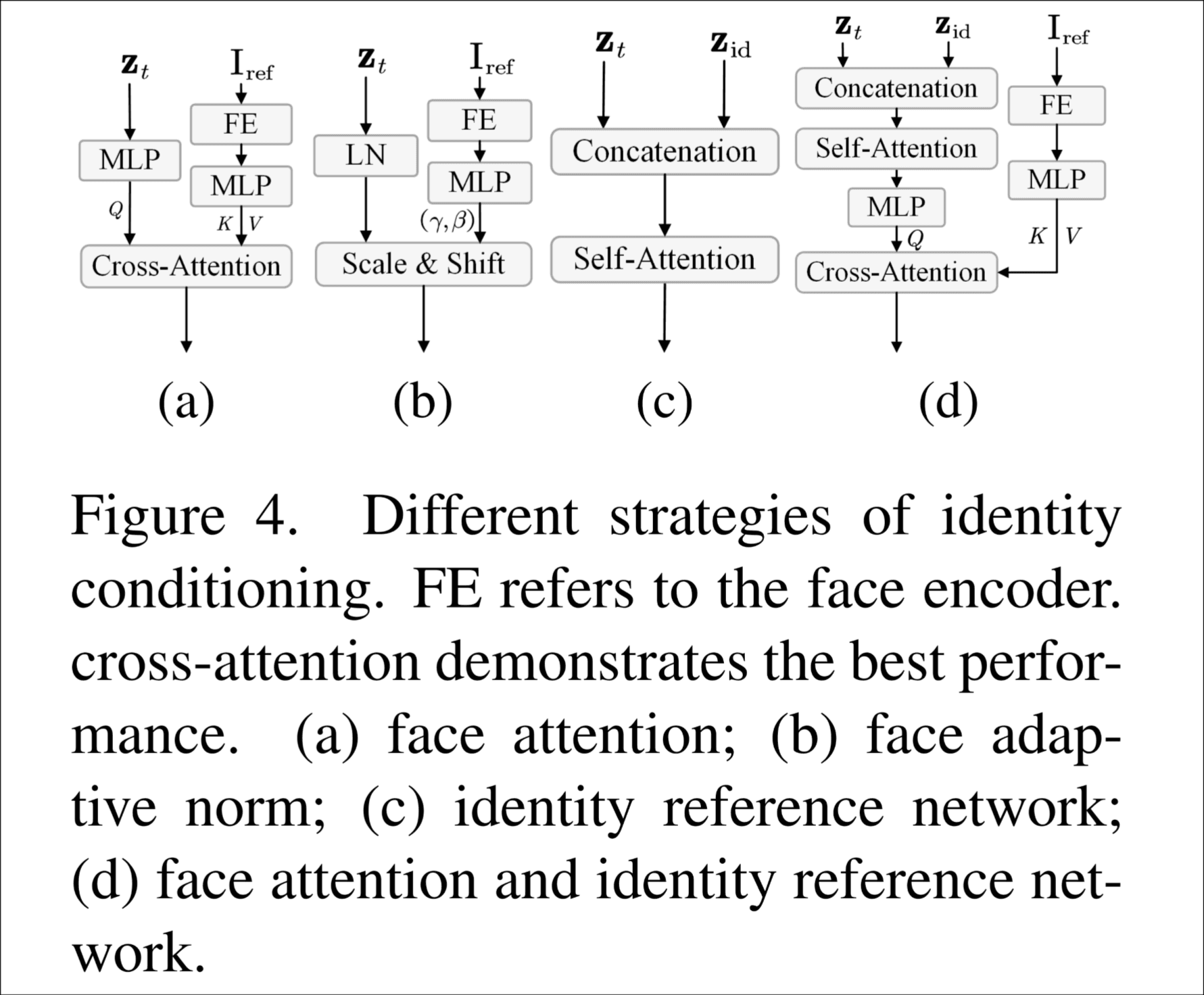
身份保持 Transformer
4种方法, 直接看图吧, 最后实验发现方案d最好.
就是上图中Identity Reference Network的输出, 与animate anyone中的ReferenceNet一样的思路.
为了长视频生成的能力, 把前n帧也作为条件输入, 这里用的EDGE中看到的方法, 假如要生成视频的长度是L, 然后latent表示长度为l, motion帧是N帧, latent表示后是n帧, 对(l-n)帧进行0填充, 与l帧高斯噪声连接.
训练和推理
第一阶段训练身份保持的能力, 这一阶段没有audio attention, 专门训练ReferenceNet的3D full attention和denosed network的3D full attention和face attention.
第二阶段训练audio驱动生成, 插入cross attention并训练cross attention.
数据集
HDTF数据集(8小时), YouTube数据(1200小时), 电影数据(2346小时). 发现脏数据很多, 设计了过滤流程.
提取单speaker, motion筛选(一些评估工具计算metric scores), 后处理(clip, face特征提取).
实验
64个V100训练, 8个A100上conducted. 训练的1和2阶段都训练20000步, batch size为1, 学习率1e-5, 分辨率480x720, 视频49帧.
定量分析拿了几个数据集, 和几个相同的模型比较了一下, 达到SOTA效果.
消融实验包括: 音频调节, 身份参考网络, 时间运动帧, CFG 尺度.
感受
我发现我普遍会觉得自己熟悉领域的文章思路清晰, 结构明了.
直觉身份保持能力的实现参考的其他论文的实现, 加了个cross attention增加音频条件驱动.
其实第一阶段的训练包含一个很细微的问题, 在跑animate anyone任务中, 我使用了自己截取的图片作为参考图, 生成效果并不好, 我指出了一些可能原因, 然后师兄增加了一点, "因为这张图片未在训练集中, 模型没见过", 这段话放在这里没有任何含义, 仅是想到了, 于是从高层次总结作者的思路, 先处理身份保持(也让模型见过这批数据), 再增加cross attention处理音频驱动.