CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
text-to-video的基础模型, 能生成10秒的长视频, fps为16, 分辨率768x1360. 卖点是长视频和文本连贯性. 3D-VAE, expert transformer, 分阶段多分辨率训练, effective pipeline. 结果在生成质量和予以对齐上都有所改进.

介绍
视频生成两条主线, 基于diffusion和基于transformer, 目前使用Transformer作为框架的diffusion方法占主导.
这里是组会中提到的一个技巧, 让人眼前一亮的例子, 他们发现"一道闪电劈开岩石, 一个人从岩石里跳出来"这个提示词, 现在的DiT模型生成不好, 不能保持很好的语义连续性.
他们的工作就解决了这些问题, 使用下面提到的方法.
第一使用3D VAE在同时在时间维度和空间维度压缩视频, 1) 减小序列长度, 2) 促进帧间连续, 防止闪烁.
第二使用expert transformer with expert adaptive LayerNorm来促进text和video两个模态的融合. 3D全注意力在时间维度和空间维度同时建模.
第三使用一个 video captioning pipeline 准确的描述视频的内容. 他们认为网络上的数据集都缺乏对视频的准确文本描述, 准确的描述可以让模型抓住精确的语义理解.
第四progressive training. 包括 multi-resolution pack, resolution processive training and Explicit Uniform Sampling.
当前发布了2B和5B参数两个模型. 展示了一个图, 和其它知名视频生成模型的比较.
结构
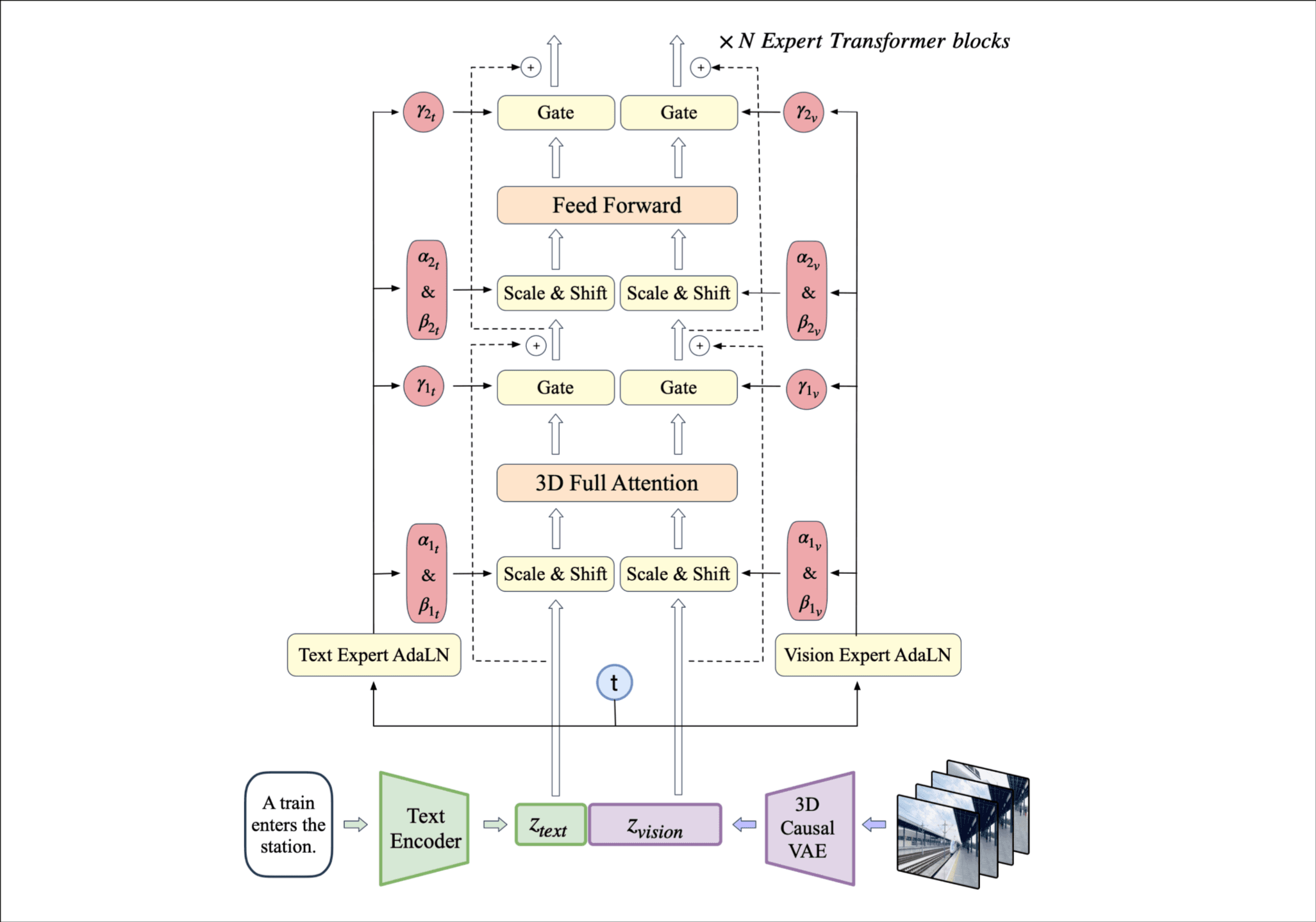
我算是理解为什么前面说他在时间和空间维度做全注意力了, video过3D causal VAE后有一个分块和在时间维度展开的操作, 记为, 然后还会和拼接(使用T5嵌入).
这整个transformer叫做expert transformer, expert应该和DeepSeek的expert router这种机制没有关系(还以为会有呢). adaLN和 Scale&Shift以前见过.
3D Causal VAE

视频同时包含时间和空间信息, 为了应对建模数据的计算挑战, 用3D卷积同时在时间维度和空间维度压缩信息, 能够实现更高的压缩率, 改善视频重构的质量和压缩率.
从上面图片中可以看出在时间维度下采样了两次, 在空间维度下采样了一次, 还包含一个Kullback-Leibler (KL) regularizer不知道干嘛的. Enc Stage 和 Dec Stage包含交叉堆叠的ResNet block.
这个temporally causal convolution对应上图中的(b), 老实说这里没有看懂, 需要找到对应的论文细看吧. (图里面的Rank0, Rank1好像是指不同的GPU设备, 是一种性能优化策略? 不管了不重要)
做了消融实验比较不同的压缩率和latent channels的效果, 介绍了训练阶段的一些配置, 这里放实验章节比较好.
Expert Transformer
Patchify. video latent的shape为T x H x W x C, 分块后的序列长度为.
3D-RoPE. 它前面patchify这一步可以说是对一个立方形从三个维度的方向切割成了很多小立方形, 我要怎么让模型知道其中一个小立方形在大立方形中的位置呢, 通过坐标(x, y, t). 坐标的嵌入通过RoPE, x和y占用3/8 channel, t占用2/8 channel, 在各个维度分别利用1D-RoPE, 最后拼接到一起. 其实我觉得嵌入做的视频一直是对一个数字进行映射, 我通过映射后的向量可以知道这个数字是多少.
Expert Adaptive Layernorm. 虽然为了text和video的同步在输入时将token凭借到了一起, 但是显然这两种模态非常不同, 甚至有不同的数值缩放, 两种模态使用不同的 Layernorm.
读者注
我竟然懂了它expert的含义, text和video虽然在输入是连接到了一起, norm和缩放过程分开处理, 有点牵强吧, 不过又好像很有道理.
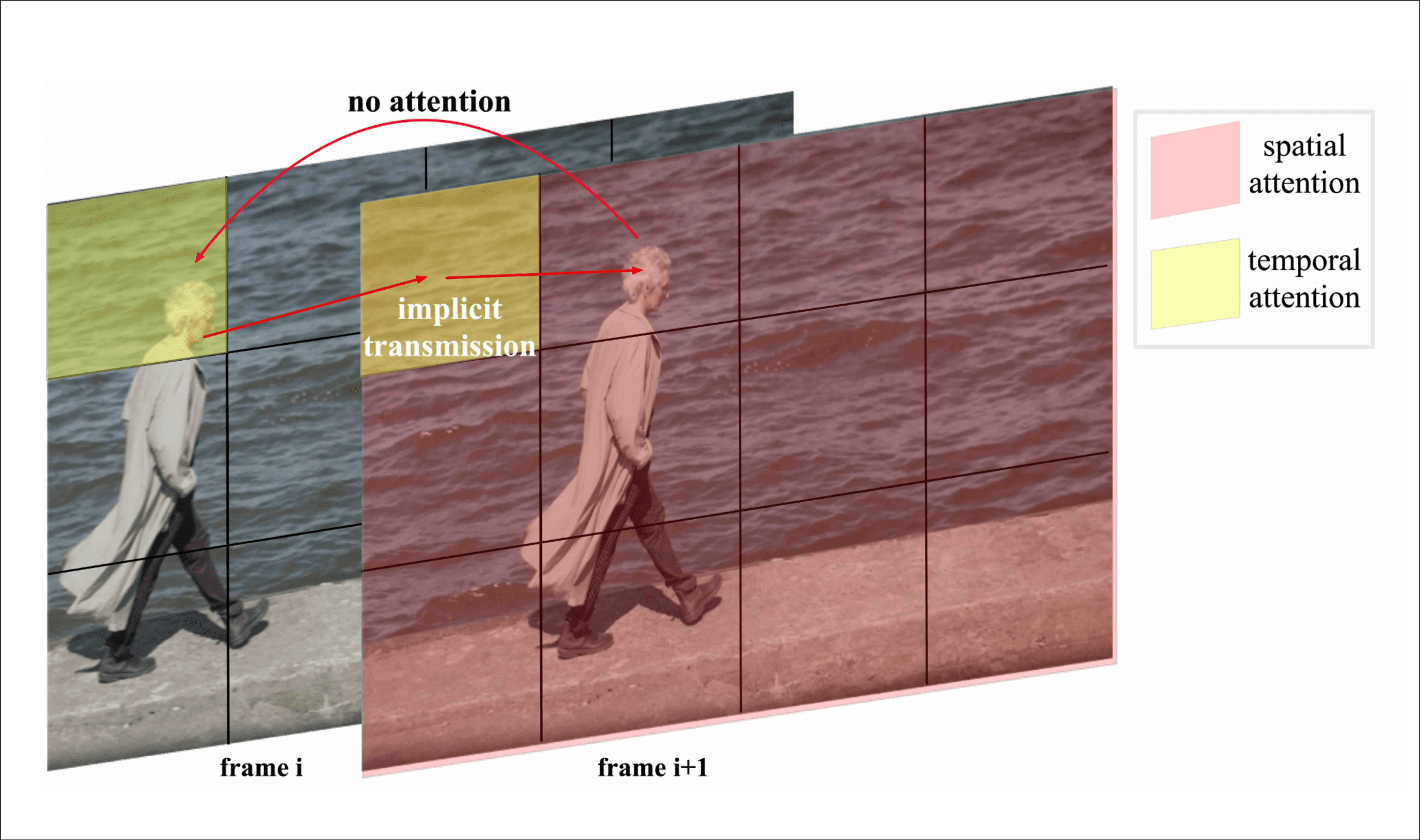
3D Full Attention. 以前的工作单独运用时间和空间注意力来减小计算复杂度, 从text-to-image模型微调. 通过下面这张图片它指出了之前方法存在的问题, 前后相邻的两帧, 人脸在第一个方块但是下一帧移动到了第二个方块, 但是时间注意力只能捕捉到不同时间维度同一位置的信息, 而空间注意力不能捕捉其它时间维度的信息, 这样的视觉交流就需要广泛的视觉信息隐性传递, 增加了计算复杂度. (这个叙述挺精彩的, 刚开始我也被骗到了, 但是前提是模型用了它前面的patchify策略, 据我所知sd v1.5就没有patchify策略, 直接在整个图片上做时间注意力)
训练
训练的时候混合和图片和视频, 图片看作是单帧的视频. v-prediction, zero SNR这些配置和sd一样.
Multi-Resolution Frame Pack
它的数据集中有图片(看作一帧视频), 短视频, 长视频, 固定帧训练存在问题, 太短的要舍弃, 太长的要裁剪, 图片和视频会根据token长度分化成两种生成模式, 不利于泛化能力.
他们想到的办法就是mixed-duration 训练. 看图好理解, 使用3D RoPE适应不同的shape.

Progressive Training
保持aspect ratio不变, resize视频为256px->512px->768px, 分步训练, 可以节约成本的说. 最后有一个高质量的微调.
Explicit Uniform Sampling
这里描述了一个现象, 在多GPU训练时, 我们一般是每个rank都在1到T随机采样, 但是timestep对loss有影响, 这样会导致loss有较大的波动, 他的方法是把1到T分成n个区间, n是rank的数量, 每个rank只在自己的区间里面采样.
Data
筛选阶段提出了一系列的负面标签
- 编辑:经过明显人工处理的视频,如重新编辑和特效,这些会损害视觉完整性。
- 缺乏运动连贯性:过渡缺乏连贯运动的视频片段,常见于人工拼接的视频或由静态图像编辑而成的视频。
- 低质量:拍摄不佳、画面不清晰或相机抖动严重的视频。
- 讲座类型:主要集中在一个人连续讲话且有效运动极少的视频,如讲座和直播讨论。
- 文字主导:包含大量可见文字或主要聚焦于文本内容的视频。
- 噪点多的屏幕截图:直接从手机或电脑屏幕捕获的视频,通常质量较差。
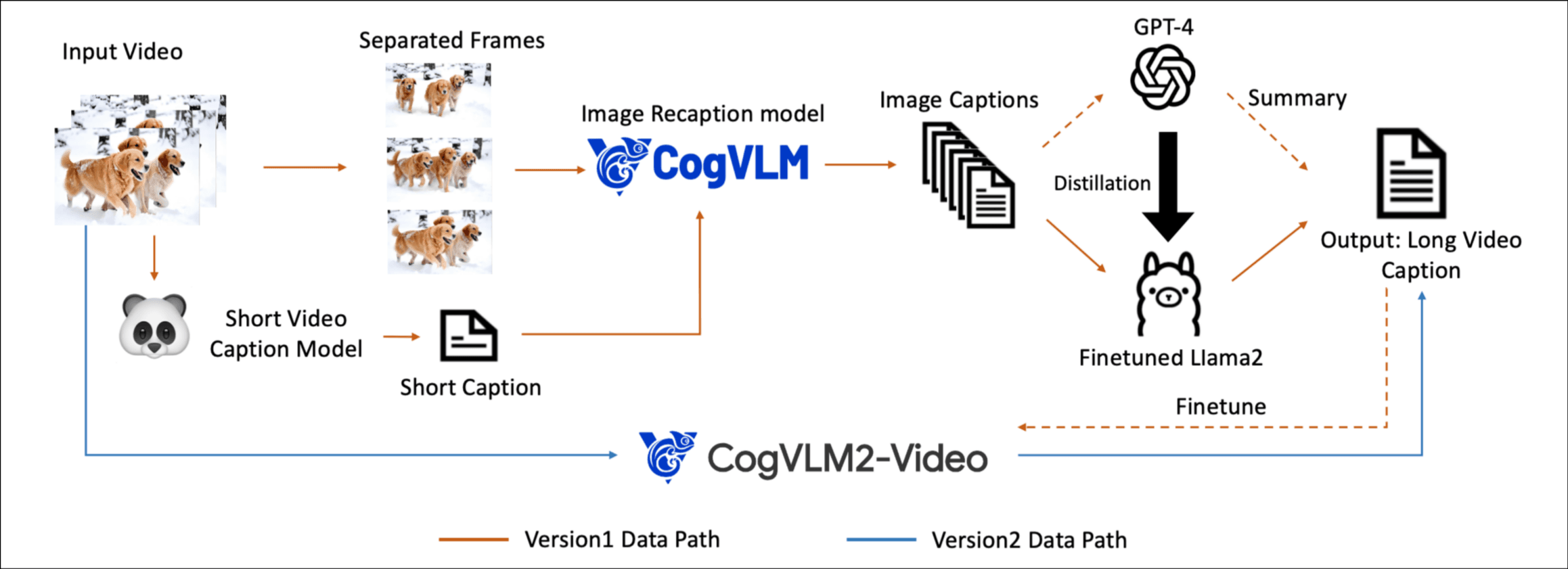
caption阶段, 看下图, 因为他们数据很多嘛, 35M条, 平均长度6秒, 使用CogVLM为每一帧生成详细的字幕, 然后GPT4对根据每一帧的字幕生成长视频的字幕.
这是一条完整的路线, 但是慢, 而且GPT4的api费用可不低. 首先它用GPT4的结果蒸馏了一个微调的Llama2, 代替了GPT4, 拿到一部分数据后用这些数据微调了一个端到端的CogVLM2-Video直接输入视频, 生成字幕.
实验
在消融实验部分
- 3D RoPE vs. sinusoidal absolute position embedding
- Expert AdaLN vs. w/o Expert AdaLN
- 3D Full Attn vs. 2D + 1D Attn
- w/ Explicit Uniform Sampling vs. w/o Explicit Uniform Sampling
在往下是VAE和模型的定量评估, 生成质量的定性评估
感受
抛开技术不谈, 这个论文风格有点像我的本科毕设(狗头保命). 3D-VAE在直觉上非常合理, 在视频生成领域会逐渐取代2D-VAE吧.
HALLO3的基础模型是这个, 想着读一下, gtihub完全开源, 生态好, 我很愿意在后面的研究中使用.
stable diffusion因为 2D-VAE 的运用, 使大规模的image训练成为可能, 在之后的一两年时间被反复作为研究的基础模型. 如果这篇文章是第一次引入3D-VAE(没有详细调研), 在时间和空间维度同时进行attention, 那么我觉得会成为一篇很有代表性的文章.
这是题外话, 很看好flow match啊, 希望可以早日出一个基模型超过DiT.