LayerFlow: A Unified Model for Layer-aware Video generation
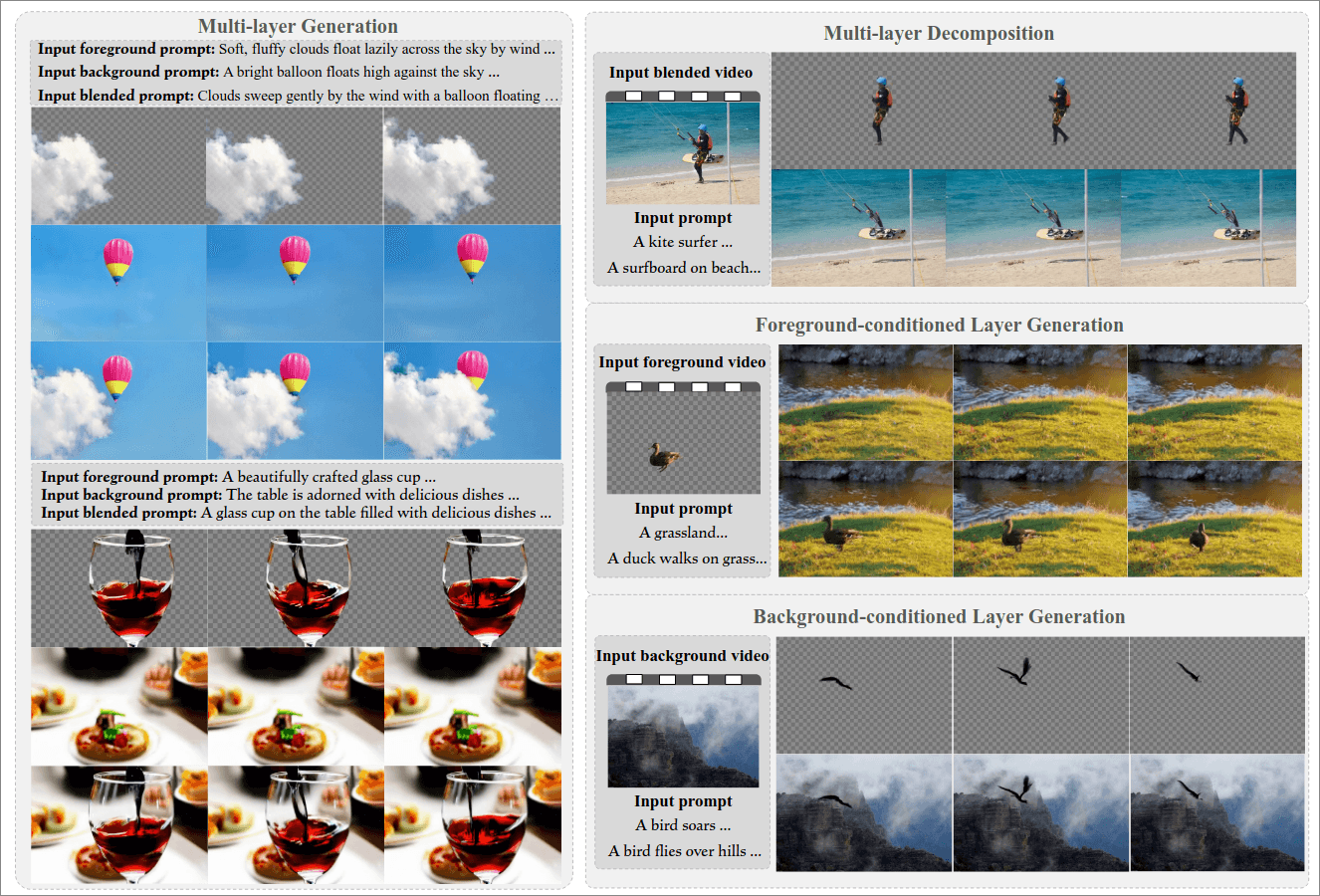
直接看图, 关注三个层次, 透明foreground, 背景, 混合场景, 用户给定每一层的提示词, 模型生成对应的视频. 由此引申出一些变体:分解混合场景, 为foreground增加背景, 为背景增加foreground. 总结工作: 1)从text-to-video的diffusion transformer开始, 把视频按前面提到的3个层次拆分, 叫做sub-clips, 利用层嵌入区分每种clip. 2)高质量数据集的缺乏, 设计了多阶段训练策略.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
讲任务: cI2V旨在从一张图片和一个条件生成满意的视频. 讲挑战: 同时生成空间外观和时间动态. 讲方法: 提出Latent Flow Diffusion Model(LFDM), 基于条件生成一个optical flow序列, 用这个optical flow扭曲图片. 训练分为两个阶段: 1) 无监督学习, 图片对的训练, 训练一个latent flow的自动编码器; 2) 条件学习阶段, 使用3D-UNet-based Diffusion预测时间latent flow. 讲优势: 之前的条件生成要同时关注时间和空间维度, 它这种方法只需要关注时间维度.
Autoregressive Video Generation Without Vector Quantization
提出了一种高效的非量化自回归视频生成方法NOVA, 通过帧间预测和集合间预测, 实现了高效且高质量的视频生成, 无需向量量化. NOVA在数据效率, 推理速度, 视觉保真度和视频流畅度上均表现出优势, 并在文本到图像生成任务上超过了最先进的图像扩散模型, 同时具有更低的训练成本.