Papervideo Generation
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
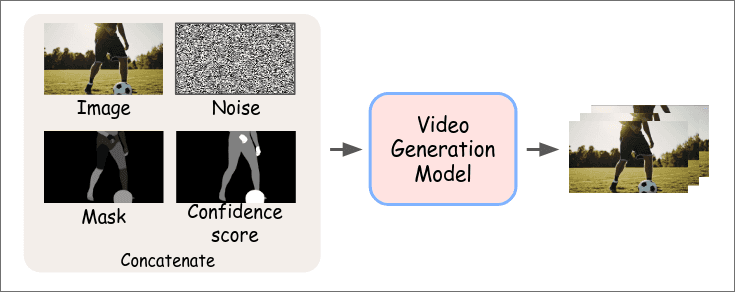
解决的问题是生成复杂的motion和互动, 训练了即插即用的ReVision, 参数量较小只有1.5B. 预置真实物理知识, 生成分3步, 1)生成粗糙的视频. 2)从粗糙的视频中提取2D和3D特征, 生成一个3D建模, 然后生成精炼的3D motion序列. 3)它把生成的3D motion序列作为额外的信息又送入了原来的模型, 得到最终视频.
Loading...
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
把Rectified flow应用到了实践, 声称表现比diffusion更好. 文本和图片使用分离的参数, 允许双向流的信息流动交流, 可以获得更好的文本理解. 声称这种结构具有可预测的拓展趋势和较低的验证损失, 改善了text to image生成能力, 达到SOTA水平.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
这是一篇科技报告, 字节跳动训练了一个视频生成基础模型Seaweed-7B. 1)性能与更大的模型媲美. 2)有广泛的下游应用